Infrastructure as Code – part 1 – Provisioning
- Processes, standards and quality
- Technologies
- Others
The following article is the first one of a series of three texts raising the subject of automation of distributed infrastructure in web projects.
In recent years, DevOps has gained significant popularity because it allows to use best practices known by developers in the world of system administrators and vice versa.
It works for me
One of frequently repeated problems in the software development process is a situation in which a given solution works in developers’ environment, and after running the application on another machine an error occurs. The reason for that may lie in the very application, incorrect configuration or hardware failure. To avoid this kind of situations, it is crucial to provide an appropriate quality of solution by:
- writing and executing different kinds of tests
- tracking and controlling changes
- virtualization
Most of all, we should keep in mind that developers are only humans, so naturally they make mistakes. A very important factor that allows to minimize the impact of human factor on the process of software development is automation. To paraphrase the famous phrase “it’s the automation, stupid” it’s important to always remember that manually performing various tasks, especially repetitive ones, is error prone.
Experienced engineers appreciate advantages of using the above mentioned practices in their everyday work. However, quite often infrastructure issues are entrusted to third parties and are treated as one-time job. Adapting dynamically evolving application to the growing number of users and their needs can cause that such approach to the configuration of operating systems is disastrous. To avoid problems, the simplest solution would be to reproduce all the developers’ best practices and apply them to infrastructure. Thanks to this approach we will gain the following advantages:
- documentation of infrastructure – instructions for configuring the operating system in the form of code will be available to both, developers and those responsible for the environment
- reproducibility and portability – configuration process may be repeated in an identical manner, giving exactly the same effect on many different machines and even on different operating systems
- testability – we get an opportunity to test the system settings
- inspection and tracking changes – changes in the application code are directly linked to changes in requirements relating to infrastructure, you can undo the changes
- savings – automation reduces the time required to prepare the system; it also reduces the risk of an error and thus eliminates additional work on solving random problems
Provisioning
In software engineering we understand it as a set of automatic actions that are intended to prepare the server to work through an appropriate configuration of the operating system parameters together with a network interface and access rights, as well as installation of the required software and collecting necessary data. Generally, this phrase can mean all operations starting from the creation of a new clean machine, and ending with bringing it to the state in which it is fully prepared to work properly.
In practice, preparation of provisioning comes down to describing the desired state of the operating system using objects of specific classes, defined properties, relationships and information flow. As an example of such objects, we can give a file that has a specific checksum, a catalogue with certain permission, service that is started or stopped or software that is installed on a specific version. When we have such instructions of system preparation, a process consisting the following elements is started:
- Collection of facts – information about the current state of the system and the objects contained in a prepared set are collected
- Comparison – data collected in the first step are compared with the defined final state
- Application – if the second step detects some differences any necessary changes are applied
- Notification – if there is a change to dependent objects, information about the existing event is passed, e.g.: change in the service configuration file requires restarting this service
A very important part of the whole process is the layer that translates abstract description of system objects, together with actions taken on, to specific commands run in a particular operating system. Each object class has an assigned, so called, provider for a specific operating system.
Another key words associated with the provisioning process is idempotence. What lies behind this phrase is a strictly defined behaviour of objects during the system configuration ensuring that absolutely no action will be taken on the elements of the operating system if their condition is consistent with the desired one. The objective of this approach is to ensure the continuity of the system operation. An example would be a service configuration file and its status. The content of the configuration file is generated whenever provisioning is carried out based on a template with the variables to a temporary file. Then, the target and temporary files are compared to each other by a checksum. If difference is detected, file is swapped and dependent service should be advised of the need to restart certain service. If the change wasn’t detected in the file, there is no need to notify service.
Tools
Currently, there are many applications for provisioning on the market; they are mainly open-source software. They have also paid counterparts, with support for corporate clients. Ones of the popular tools for automated configuration management are: Opscode Chef, Puppet and Ansible.
Opscode Chef
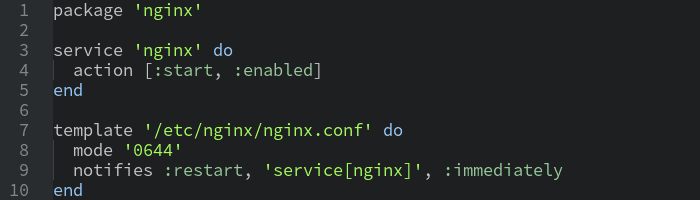
Chef is a cross-platform tool, which allows to configure many different operating systems. The basic version allows remote connection using the SSH service and accomplishment of all the operations necessary to prepare for work. There is also a client-server version with one central point providing all necessary information and any number of nodes on which a client application runs that connects to the server to download instructions for setup. Chef was equipped with a tool gracefully named knife to automate all administrative work related to the very Chef and more. A unique and very useful feature of Chef is the data bags system for storing data. However, the uniqueness of this solution can be fully used when working with a client-server architecture. Only then, functions for storing data, generated during provisioning, become available. For example, if one node was designed to work as a database server with a specific user ID and password, the data may be stored on the server and used in the preparation of the web server. Chef is written in Ruby, and it is possible to expand its functionalities only in this language.
Puppet
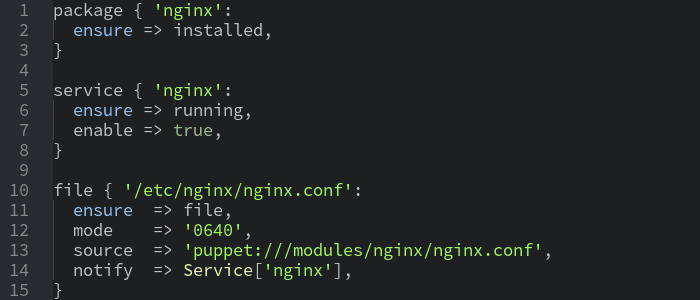
Puppet is also a cross-platform tool. Similarly to Chef, it has two variants of work: stand-alone and client-server. To describe the system a declarative language is used with a structure similar to JSON. Puppet was equipped with code generator, which is capable of producing ready-for-use pieces of manifest files. The use of such a solution resulted in the significant improvement of learning how to work with this tool. Since Puppet has been written in Ruby, all its extensions are based on this language.
Ansible

Ansible has become a cross-platform tool relatively recently, beginning with the version 1.7 (August 2014). In contrast to Chef and Puppet, it doesn’t have a client-server version. It can be run remotely via SSH. Infrastructure is described using a simple and descriptive language based on YAML. Ansible functionality can be extended in any language, since the modules are designed as independent elements. The creators guiding principle is that the tool was inherently a minimalist instrument (minimal in nature).
In the next part
The next article will present the subject of infrastructure virtualization at the level of software developer environment. One of the most popular applications to automate the process of creating a local virtual machines that makes work easier for both, developers and administrators who want to test their solutions, will be discussed. Vagrant – because it is the topic of the next article – was also integrated with popular tools for provisioning. Consequently, it is a compulsory position in a library of software engineering tools.
Maybe you’ve noticed, or not, we’ve introduced a new option on the blog – „suggest a topic”. Let us know about your problem / suggestion to broaden a topic, and we will try to respond to your request with an article on the blog.