- Processes, standards and quality
- Technologies
- Others
This year’s JDD conference was once again held in Galaxy Hotel in Krakow. 13th and 14th of October are the days worth remembering and summarizing. This time there were 4 paths of lectures presented during the first day and a mix of workshops and lectures on the second day. Below is a summary of the most interesting presentations.
Crazy fast build times or when 10 seconds starts to make you nervous by Daniel Bodart
Paweł Benecki’s review:
Quite interesting lecture, based on practice. The author approached the problem of build duration from a few perspectives: language, compiler, tests, building tools, servers, operating system and hardware.
Everything was based on speaker’s experiences in one of his last projects. The project was consisting of 150k lines of code and it used to be built for about 45 minutes. After build optimization this time was reduced to 3 minutes while retaining (logically) the whole scope of the slow build.
Of course, some mentioned things were quite obvious, however putting all the information together is valuable. It isn’t always necessary and reasonable to forcibly make build faster. What is more important – we should rather keep in mind all the following things during day-to-day development to not make builds slower.
Language & compiler
While it’s rarely reasonable to change language just because of build duration, we should remember that scala code is compiled about 5 times slower than Java. Also version of java makes a difference: Java 7 compiler is the fastest one. Bad news is that Java 8 has much slower compiler than the 7th version. And it gets slower with every Java 8 update. Developers should know and use advanced java and compiler options. For example -XX:+TieredCompilation helps a lot during builds, as it makes single jvm startup faster.
Build tools
As ant / maven / gradle are some kind of standard, some critical parts of build could be rewritten. The author mentioned an example in which they wrote a Python meta-tool generated from pom.xml-s for a slow-building module that did the work a few times faster than a standard build. Daniel also mentioned https://code.google.com/p/jcompilo/ which proved to be useful for him as well.
Dependencies
Usually, Maven repositories are slow. It’s possible to create a maven-like repository on S3. Daniel claimed that despite being in cloud it was still faster than a local artifactory.
Tests
You shouldn’t use separate sets of builds – slow (i.e. with test) / fast ones. That never works in a longer perspective. Parallelization of tests is also a good thing. As it comes to spring tests turning lazy bean initialization on also helps.
The team should continuously refine test set, which apart from adding new means also remove redundant / rewrite slow tests.
Avoid writing too many integration tests – rather enforce code contracts. Use embedded databases.
Hardware
Obvious thing – use SSD drives where possible.
Operating System
The dependency between OS and build time is as follows:
t(Windows) > t(OSX) > t(Linux)
Strategic refactoring by Michał Bartyzel and Mariusz Sieraczkiewicz
Paweł Benecki’s review:
Very well presented lecture, which showed technical and business perspectives on refactoring process and described factors which should be considered during projects.
The speakers differentiated „everyday” refactoring and “strategic” one. The former is something which rather allows retaining hygiene of code, while the latter is something that should allow making project better and easier to develop. Here is a picture summarizing that:
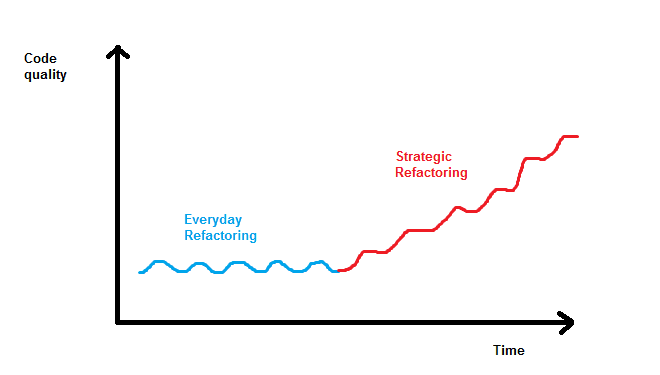
The team should always balance pros and cons whether to start refactoring, especially in highly legacy code. There is no silver bullet method to tell which option is better. A development team should not insist on refactoring, when there is too much risk compared to possible benefits etc. Sometimes, it isn’t worth doing that and we should leave things as they are.
The main process that should take place after positive decision is that we should actually stop making the code worse. And here goes „everyday” refactoring. In that area Michał and Mariusz noticed that often massive simple refactoring doesn’t bring so much value as we would expect and we also should not focus on gadgets like introducing new fancy library.
What is crucial is that the team should have common rules and understanding in areas of system architecture and mechanisms. The authors mentioned “architectural mantra” idea here and usefulness of various tools for visualization project structure (e.g. http://structure101.com/).
When analysing project structure it’s always important to guess/find historic and contextual reasons to answer the query: „why is it written like that?”. Changing approach to legacy code from emotional to rational helps a lot and allows you to work out changes plan more effectively.
During refactoring it’s good to use some concepts from DDD – splitting into Domains, introducing Domain Language, Core domain, Bubble Contexts, Anti Corruption Layer where it’s unreasonable to change internals of legacy code.
All planned changes should be formally written and the team should work out process of introducing them and stick to it.
High Performance Logging by Peter Lawrey
Daniel Kostrzewa’s review:
During the lecture Peter reminded that extensive logging can slow down application. It is crucial to save logs just before application crashes. Unfortunately, almost every logger works asynchronously so there is risk that the most important information about the reason of the crash can be lost.
Peter introduced Chronicle Logger (https://github.com/OpenHFT/Chronicle-Logger) which is an extremely fast java logger. It can aggregate all logs to a central store and supports most of the standard logging API’s including slf4j, log4j and more. Chronicle Logger is built on Chronicle Queue. It is a low latency, high throughput synchronous writer.
At the end of the presentation Peter showed some experimental results. He compared Chronicle Logger with the most popular loggers in Java world. The outcomes were really stunning. It turned out that Chronicle Logger is a few times faster than all other loggers.
In my opinion presented tool is worth introducing to many Java projects.
Game of throneware, or how to not get killed, when a developer becomes a manager by Jakub Nabrdalik
Daniel Kostrzewa’s review:
In his lecture, Jakub presented very common scenario, when a developer becomes a manager. He pointed out that in most cases developers are not prepared to be good managers. He also mentioned that developers are not very good in communication so they must pay attention to this area.
The speaker advised how to organize teams and workspace. He believes that positions of team members’ desks have huge influence on productivity and must correspond to system architecture. He gave some hints about making decisions, dealing with salaries, outsourcing, investors and so on. Jakub also told us how to hold a conversation with other managers on crucial meetings.
It was a great pleasure to participate in this presentation with a pinch of humorous comparisons to the TV series Game of Thrones.
I highly recommend viewing this lecture at the earliest opportunity or when it will be available online. In my opinion it was the best talk at the conference.
Using ASCII Art to Analyze your Source Code with Neo4j and OSS Tools by Michael Hunger
Łukasz Grabski’s review:
A world we live in is a graph. A graph that emerges from whole of entities we interact every day and all possible relations between them: be it your wife, boss or a lady selling cigarettes at the train central station.
Getting closer to IT itself; just think of your everyday work – we have structured source code, managed project multi-level dependencies, branches and tags in VC systems, JVM Heap, etc. All of those are just graphs of interconnected data units with specific relations! What if we could use graph theory to analyze their complexities? I bet you know the answer ;). We can do it with Neo4J graph database :).
Luckily I had a chance to meet Michael Hunger, one of the Neo4J developers, on latest JDD conference that took a place in Cracow lately. During 45 minutes speech one could learn just briefly what is this thing called a „Graph Database”, how does it differ from casual SQL (schema less for the win!), and when choose one over another approach.
After short intruduction Michael went directly into some details with Neo4J query language so called „Cypher” (any „Matrix” references?) giving some examples of it’s grammar together with some interesting use cases including creating and querying graphs contents.
Finally Michael presented some interesting Open Source Tools that could be used together with Neo4J database to analyze source code structure complexity thus make Graph a tool for static code analysis like jQAssistant (http://jqassistant.org/).
One would ask – „where is this Art mentioned?”. It’s Cypher itself 🙂
(Cypher) – [:FEELS_LIKE] -> (Art)
Docker.io – Versioned Linux Containers for JVM Devops by Dominik Dorn
Łukasz Grabski’s review:
In this presentation Dominik Dorn gave us a glimpse of technology that is about to change rules of the game in the world of virtualized environments.
I need to say I felt very comfortable attending a speech that has barely five-six slides whereas the most of the time author spent on real life use cases and live examples :).
Having two or more shell consoles running at the same time, we had a chance to see Docker in action including:
- capabilities of Onion filesystem together with it’s versioning and branching features
- dropping jaw effect caused by incredible fast boot up speed!
- using powerful Docker templates
- usage of “Fig” tool to make Docker usage easier
- it’s integration with „Docker app store” (https://registry.hub.docker.com/)
Dominik’s speech was one of very few that attracted my attention till the very end, probably because of many live examples that just worked, no strings attached.
Hope you enjoyed it as much as I did :).
What your code says to you by Mariusz Sieraczkiewicz
Adam Kulawik’s review:
Mariusz Sieraczkiewicz gave an interesting and inspiring lecture on a software craftsmanship, in which he focused on how developer could work with an existing source code.
The introduction to the lecture was dedicated to how human’s brain works, and how it affects software development. In general, information gathered by people are divided and then, basing on their similarity, grouped into pieces called chunks. Subsequently, they are transferred to a short-term memory, which has small capacity, but works fast. At the end of processing those data might be stored into slower, but also much larger, long-time memory, which structure recalls a mind map. Mainly short-term memory works during development and therefore it is prone to cognitive load, which can be caused by:
- redundant information, e.g. comment duplicating information already expressed by code
- split attention effect, e.g. too early initialization
Concluding the introduction Mariusz highlighted that modern software engineering rules are more compatible with a way human’s brain works than to mathematical models.
In the following part of the lecture the speaker discussed the code intelligibility. As a possible method of verifying it, he presented proposed by Michał Bartyzel method in which developer could pass a slightly transformed code to speech synthesis and verify whether result is understandable. Mariusz discussed here some techniques of improving code readability:
- Introducing Domain Object instead of primitive type
- „Flattening” if conditions i.e. using many conditions in if statement instead of nesting it, however this should be done reasonably; it may be worth categorizing conditions before
- Excluding code bounded with conditional statements into private methods
- Name class fields in context of class name, i.e. it is pointless to name field like personName in Person class
- Implementing null object pattern instead of checking null references
- Fluent naming and reading convention e.g. controlSumFor(SSN)
At the end the speaker mentioned JDeodorant tool, which can help in identifying potential code smells.
Further reading:http://mbartyzel.blogspot.com/2013/06/code-speaks-2u-czyli-test-ivony.html (in Polish).
Conversation Patterns for Software Professionals by Michał Bartyzel
Adam Kulawik’s review:
An interesting lecture dedicated to communication between IT and business. Topic was introduced with two stereotypical statements about how both sides see each other; while developers believe that client doesn’t know what he actually needs, business people say that IT people don’t think in business way. The speaker focused on how IT professionals should talk with stakeholders about their needs.
The main thesis brought by Michał was that client has one of two main motivations: either to avoid a hassle or to benefit from software, and that his needs should always be in the centre of the whole communication process. The speaker described the way that development team could approach while gathering user stories. Good practice is to invert „as a role I want system to do something so that I can reach my goal” schema into „In order to reach my goal, as a role I want system to…” as this puts stakeholder’s needs at first place.
Furthermore, it should be specified whether the business goal is to avoid something, or to reach something i.e. „In order to avoid problem…” or „In order to reach expected benefit…” respectively. Therefore, if customer wants to avoid problem it is advised to approach it with a pattern questions such as:
- „Why?”
- „What made you need?”
- „What is the difficulty?”
- „What is to lose?”
- „What do you want to avoid?”
while for benefit-motivated needs it is suggested to ask:
- „What for?”
- „What will it give to you?”
- „What is the purpose?”
- „What will make it possible”
Beside this some communication related issues were highlighted:
- It is crucial to ask why required functionality is so important as the real need might not be expressed explicitly
- Asking many technical questions in response for change request can be considered by business people as aggressive rejection
- Acceptance criteria are always specified by business
- People often tend to answer their own interpretation of question
- It is very important to try to structure conversation as it can easily drift towards chaotic digressions
JVM bytecode manipulation techniques for JVM „freaks wannabe” by Jarosław Pałka
Marek Ozaist’s review:
Jarosław started with introduction to bytecode structure. Its format is defined by class file format specification. There are many defined operands – ALOAD, DLOAD, ILOAD, FLOAD (each java type has different operand, A is for reference type), ASTORE, DSTORE, ISTORE, FSTORE, DUP, POP, GETSTATIC, LDC, RETURN, GOTO, IF, INVOKEVIRTUAL, INVOKEINTERFACE, INVOKESPECIAL, INVOKESTATIC, INVOKEDYNAMIC (each method type has separate operand) and many others. Invokedynamic is new operand added in java 8 to support lambdas. Then he told about constant pool and how stack works.
JVM has a bytecode verifier, which checks if there are errors in bytecode before code is interpreted.
The second part of presentation was about java bytecode libraries with examples of their usage:
- Asm: bytecode manipulation library. Difficult to work with. Jarosław showed example of how to create class with private field and constructor. It is possible to generate class in memory and write it to .class file.
- Jitescript: It is easier to use than Asm. The example showed how to overwrite compare method in IntComparator class.
- ByteBuddy: It is easier to use than Asm. The example showed how to overwrite toString method in any class.
- Byteman. We can easily add annotation to unit test, which for example throw exception if constructor of File class is called.
- JavaAssist: different concept than ASM, it is more focused on class files and concept of ClassPool, similar to ClassLoader. The example showed how to add printing text before method in our class is called.
import allegro.tech.internal.* or building technical backend in corporation by Adam Dubiel
Marcin Perczak’s review:
During presentation by Adam Dubiel, a tech-lead in Allegro, responsible for delivery of services, one was able to get familiar with microservices based architecture. Until recently Allegro used a few bigger applications, which like a big balls of mud were constantly being enriched with new functions. This caused problems with scalability and maintainability. At that time it was decided to switch to microservices. During the lecture Adam briefly described the concept of microservices, with pros and cons. It wasn’t a mindchanger, as the idea has already spread throughout the industry, until Hermes was mentioned. Hermes is the all new treasure implemented by developers from Allegro. It is a publish-subscribe solution based on project Kafka. It allows quick clustering, supposedly being able to handle 30K requests per second with response time below 50ms.
The question one could ask is how the Hermes differs from Kafka. According to the lecturer Hermes is a next stage of Kafka, you could call it Kafka++, it’s enriched with new functionalities e.g.:
- REST interfaces (Kafka uses its own client);
- management module and ACL (Access Control List) were added;
- multiple consumers, implementations can be based on HTTP, JMS, WebSockets;
- notification policy is enriched, it is possible to go “back in time” in case of a failure and set it up at a specific point;
- better monitoring was introduced, using event ID one is able to investigate entire flow of an event.
At most points it sounded interesting, however it also sounded a bit like a PR action, showing „how cool is our company”. What is good news though is that Hermes will be available for Open Source community before end of this year, making it a great Christmas gift. In my opinion it is worth waiting a while to see for ourselves how useful this solution can be, using e.g. docker.io.
Rather good presentation, especially as some other Allegro projects were shown, also to be made available for OS community. As soon as Hermes does emerge, it should be documented in further details on allegrotech.io.
Fearless developer road to driving technical change by Grzegorz Duda
Marcin Perczak’s review:
Second lecture I’d like to summarize was held by Grzegorz Duda. It was last lecture during the first day of conference and I was hoping for something rather lightweight. And so it was. Grzegorz focused on problem of introduction of new technologies into projects or whole companies. He described a CDD methodology (Conference Driving Development) which is simply the eagerness to introduce something new by a developer after a conference.
He divided workers in few groups:
- people who don’t use new technology because they haven’t heard about it;
- people who follow the herd;
- people who already tried something new, but it didn’t work out well for them;
- experts, who can only be convinced by technical facts;
- people who are always against as this is their nature;
- bosses who in most cases count the ROI.
Grzegorz pointed out that it doesn’t really matter what language we use while trying to convince someone to something new. It is clear that different communication style will be used when talking to CEO but talking to a developer is all about which group is he in. Sometimes essential facts will do just fine, sometimes something more is required. Lecturer also mentioned that one should always be cautious when coping with new stuff that is not yet verified by market, domain, users. It is crucial to remember that when introducing something new we will have to handle the cost of such change so that others don’t get discouraged. All this sounded quite obvious, however it was nice to hear. I’d say it was a perfect ending of a great day.
How to defeat feature gluttony by Katarzyna Mrowca
Karol Krzyżak’s review:
A thought-provoking presentation. The aim of the presentation was to show how can we extract the most valuable features from a never-ending list of wishes.
Katarzyna Mrowca presented the topic with humour while not forgetting about the valuable guidelines.
She showed us the way through the skills sets of the corresponding
- questions
- Why should we care?
- What is the root cause of it?
- Why is it bad?
- Usability
- rules
- do not try to teach „business” to do business
- setting common goal
- steps
- define use cases
- decide how to measure
we are able to define the most important business process in our application.
There were also two graphs. The first one presented how a number of features affects the complexity of the project (exponentially). The second one, the more interesting, portrayed the state of user satisfaction on the amount of introduced features. The existence of a point described as „very happy” to which we aspire, but which is also easy to overlook (cross).
An interesting fact turned out to be a reference to the Pareto principle also known as 80–20 rule. According to this rule, 80% of users uses 20% of the features.
Summarizing presentation with the words „Keep it lean” is the most accurate.
Reactive Java by Tomasz Kowalczewski
Karol Krzyżak’s review:
During the presentation Tomasz showed basics of reactive programming and a small, simple usage of RxJava library building Tweeter client.
…”RxJava is a Java VM implementation of Reactive Extensions: a library for composing asynchronous and event-based programs by using observable sequences.
It extends the observer pattern to support sequences of data/events and adds operators that allow you to compose sequences together declaratively while abstracting away concerns about things like low-level threading, synchronization, thread-safety, concurrent data structures, and non-blocking I/O”…
More information about RxJava can be found on the Wiki Home and the Netflix TechBlog post where RxJava was introduced.
Tomasz put together synchronous and asynchronous. It was easy to notice what impact of network latency has on synchronous system. However, the insertion of asynchronous is not the last thing to keep in mind. To make sense we should also be aware of making parallel operations on the server side, otherwise application of asynchronous doesn’t make sense.
Another very important tip is to use the rule which says:
Display the data that we have, we do not wait for everything to avoid delays in providing information to the user. It is very important when we get the data dynamically.
The next stage of the presentation was to show how to use the RxJava library on simple Tweeter client application. Aspects such as streaming, filtering and throttling were discussed.
In my opinion it was one of the best presentations of this year’s edition of the JDD.
How to involve a domain expert into modelling – visual and linguistic DDD techniques by Sławomir Sobótka
Adam Brodziak’s review:
This talk was presented in Polish, its original title is „Jak wciągnąć eksperta domenowego w wir modelowania – wizualne i lingwistyczne techniki DDD”. It used linguistic techniques that are typical for Polish language. Nonetheless, I’ll try to get the gist out of it, because approach and way of thinking is applicable to any natural language.
The most important takeaway from this lecture for me was: naming is very powerful, because it affects our thinking. Also naming things is the most difficult thing in computer science, a famous quote by Phil Karlton. In order to avoid running into rabbit hole with putting labels on objects we should avoid putting names on classes as long as we can. Sławek suggested to use gibberish game for naming, or just put a „Blah” name first. From practical perspective it helps to avoid generic names like manager, resource and such.
Object Oriented Programming is about message passing, events and signals – not sticking together procedures and data structures. Hence Object Oriented Design should focus on mentioned behaviours and system events, which will operate on objects. After we’ve got actions and relevant objects it’s way easier to name classes. The proper order of Object Oriented Analysis is then as follows:
- Behaviour, action, operation (technically: method)
- What does it do?
- Behaviour rules (technically: method implementation)
- How does it do it?
- Data that is processed (technically: attributes)
- What is the thing?
- Name (technically: class name)
- What it is?
Above rules help to get a common ground with domain expert while designing domain model of the system. The goal is to have names in code that are understandable to business. It’s not only about class names, but also methods and even their implementation. Take a look at the following piece of code – it reads almost like a prose:
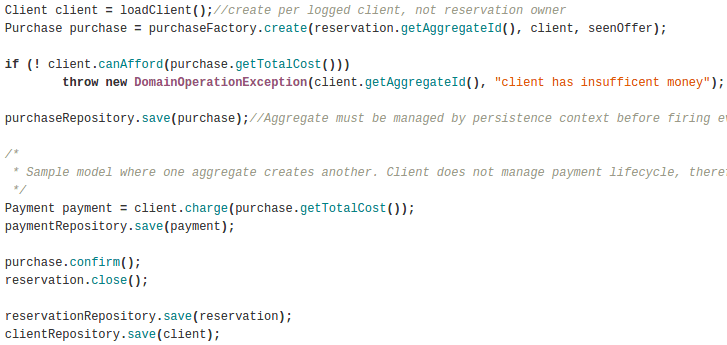
Try a trick with that piece of code: strip all Java-specific language constructs from it and give it to a non-technical person to read. If they grasp it, then it’s good code. Such technique is called „IVONA test„, a term coined by Michał Bartyzel. You can even use „IVONA text-to-speech software to try it yourself.
Another protip for object analysis with domain expert is to note down everything expert says. Not only gives us the record, but also lets find out illogical statements and missing pieces of the puzzle – things software engineers are pretty good at. Furthermore, it’s a base for linguistic analysis, that translated to object analysis quite nice. Here’s how parts of sentence translate into programming language constructs:
- To reservation add product, given quantity
- Subject.predicate(object)
- Object.method(parameter)
- reservation.add(product, quantity)
During the talk the speaker touched on many other aspects of Domain Driven Design. Many of them deserve their own blog posts, so let me just list them:
- Whirlpool Model Exploration – knowledge flow between expert and modeller
- how different people see system (and objects in it) differently
- why estimations based on GUI mockups are bad idea
- why process does not tell you everything
- visualisation techniques
Overall the lecture was packed with knowledge from different domains (linguistics, visualization, knowledge exploration, cognitive science, object oriented design, DDD) with great jokes incorporated at the right moment. Even though talk was light in terms of perception and entertaining. It is definitely worth watching if you have got a chance. Thank you Sławek.
Introducing Groovy into Java project by Yuriy Chulovskyy
Marek Ozaist’s review:
Yuriy started with showing that it is easy to change Java to Groovy. We can start with changing file extension .java to .groovy and it works! Then, we can remove semicolons, publics etc. – all stuff that groovy doesn’t need.
Then Yuriy showed many examples in groovy with comparing to java:
- @EqualsAndHashCode: groovy class annotation used to assist in creating appropriate equals() and hashCode() methods.
- @ToString: class annotation used to assist in the creation of toString() methods in classes e.g. @ToString(includeNames=true)
- three quotes (“””) – instead of escaping json in java like this \”key\”:\”value\”, in groovy we can do like this: „””\
“key”:”value”
“”” - with – in java:
Dog dog = new Dog() dog.name = 'Rex' dog.age = 2
in groovy:
dog.with { name = 'Rex' age = 2 } - new – in groovy we can create classes like this: new ClassName(par1: “val”, par2: “val”)
- ? – to check if list isn’t empty we can use ? e.g. contracts ?
- ?: – we can use it to return default value if it isn’t null e.g. value ?: defaultValue
- ?. – using ?. we don’t need to multi check if != null e.g. contracts ?. get (0) ?. clientName
- easy create list with values e.g. List<integer> list = [1,2,3]
- operations on list e.g. list.any { it.clientName == “name” }
- creating maps: map = [a:”b”, c:”d”]
- @Singleton – easy create class which is singleton
- JsonBuilder() – we can easily create json e.g.
new JsonBuilder().people { person { firstName 'Guillame' } }.toString() - testing with asserts: assert contracts = [“value”]
- testing with spock many parameters e.g.
expect:
someMethod(a, b, c) == d
where:
a | b | c | d
1 | 2 | 3 | 4
2 | 3 | 4 | 5
Object-relational mapping of true objects by Sławomir Sobótka
Adam Kulawik’s review:
An impressive, as usual, presentation by Sławomir Sobótka on ORM related issues in the spirit of DDD.
Sławomir began his lecture with short guide what true objects are; explained that object is a being who can receive signals from the outside, and that good object is apathetic, introverted and selfish. He also mentioned that original JavaBeans get/set convention was intended to manipulate GUI components’ properties, not object themselves.
After introduction Sławomir discussed how ORM tools, like Hibernate, and repositories should be used properly. The first typical problem faced, is LazyInitializationException, which according to him can be avoided easily by using Eager loading strategy and read whole data aggregate at once. This solution, of course, may result in loading too much data, however if boundaries of the aggregate are specified properly, according to DDD rules, the size of fetched data should be correct and appropriate. The speaker suggested here, that object should consist only of data required by its business rules.
Another issue connected with using ORM is possibility that data stored in database would be modified between read and write operations. As solution to this Sławomir suggested using optimistic locking for a whole aggregate. It can be reached by using @Version annotation and setting up a lock strategy:
- OPTIMISTIC for read operations
- OPTIMISTIC_FORCE_INCREMENT
It was also advised to use cascade writing for the whole aggregate. Regarding this the speaker encouraged to prepare own repositories in which these locking strategies realised by EntityManager.lock method can be encapsulated.
At the end, Sławomir mentioned CQrS approach considering a case in which a usage of two databases, synchronized by events, might be reasonable. He discussed that in some cases (i.e. product displayed with information about social media friends interested in the same product) might be reasonable to use graph or document database as the “query” database. The lecture ended with conclusion that for some applications the best option might be to use non-relational database.
Further reading: http://bottega.com.pl/pdf/materialy/receptury/orm.pdf (in Polish)
Java Enterprise’ish development without hassle by Jakub Marchwicki
Adam Brodziak’s review:
Coming from different background typical approach to web development in Java always surprised me. As soon as the need for RDBMS was identified, Java developers are starting to shout: Hibernate! JPA! – then arguing which one is better. Similar thing happens while discussing frontend part of a project: JSP, Spring MVC, JSF, PrimeFaces or GWT from the more experienced and lazy ;). After some time I’ve learned simple rule: if there’s a problem – there’s Java framework for that.
Jakub shares similar point of view – all those frameworks are great, but quite often they are an overblown. There’s no need to fire a missile against a mosquito, unless you’re Monty Python crew, of course. In Jakub’s own words: Spring was lightweight in 2006 – at the time when bulky JEE applications were the blessed way to make web app. Currently, we’re observing the opposite trend – instead of hiding everything behind abstraction, embrace the power of underlying technologies, like HTTP and SQL.
Besides sarcastic jokes about mindless developers, the core of the talk was to present really lightweight libraries for modern Java stack. Jakub showed a simple TODO application written in each of them, check the code available on GitHub. Tools showcased were:
- web layer
- Jetty – lightweight servlet container and web server
- RESTeasy – a JBoss project that provides various frameworks to help you build RESTful Web Services
- Spark – Sinatra inspired micro web framework
- Webbit – event-based, single threaded WebSocket and HTTP server in Java
- Dropwizard – ops-friendly, high-performance, RESTful web services
- SQL database access
- JOOQ – lets you build typesafe SQL through its fluent API
- jDBI – exposes database access in idiomatic Java
- Sql2o – makes it easy to execute SQL statements on JDBC-compliant database
Benefit of going „down to the metal” is simplicity. Using „lightweight” Spring Boot framework makes it easy on the surface, but hides problems behind abstractions. In consequence, stack traces in exceptions are lengthy and unreadable. In examples above if something did break you know exactly where and it’s easier to find out why. No more trying to understand which DAO could generate such faulty SQL query.
Another point in „why bother” theme is sharpening the saw. Since we’re building a web application it’s good to know the environment we’re in (HTTP and web) and technologies powering apps (SQL and relational databases). Developing small side project gives us time and place for learning, and getting into basics helps to understand the underpinnings of web development. Very good talk Jakub.