
- Processes, standards and quality
- Technologies
- Others
There is a belief among many developers that JavaScript is very slow, and writing more code in it than it’s necessary may adversely affect the performance. I guess it’s partially true. Incompetent use of this language can indeed decrease the quality of the project and the performance itself. However, JavaScript is one of the most developing languages. It’s more and more optimized and is compiled by various JS engines. Just to mention port of Unreal Engine 3 with the aid of WebGL. Nowadays, JavaScript is well optimized and we don’t have to be worried about each line. I’ll show you a few examples that will prove that JavaScript engines do what they can to speed up your code. In my work I focus on Google’s open source JavaScript engine V8. Do not be misled by the title, this article is a classic love story. First, we take into account regular expressions. I’ve always heard that in JavaScript we have to use them very carefully due to their cost. Generally, it’s a good idea to use the non-capturing groups. As you remember, they only match a pattern without remembering anything. If it’s possible, you can also split the regular expression into smaller ones or (and that would be the best idea!) replace it with built-in functions. Of course, it is better to use e.g. split method or combination of a few well-known methods as it will be faster than using a regular expression. No tests are needed for that. But do we really need to be worried about regular expressions performance? Let’s say that our goal is to validate text if it contains only days ranges (it’s the case I run across some time ago), e.g. 2-10; 12; 13-20; 22; 25; 26-29. The text may or may not end with semicolon. The easy one. As a result we get this regular expression:
var regexp = /^(((\d+-\d+;)\s*)|((\d+;)\s*))*(((\d+-\d+;?)\s*)|((\d+;?)\s*))$/g;
However, as I said before, we can use non-capturing groups to try to increase the performance:
var regexp = /^(?:(?:(?:\d+-\d+;)\s*)|(?:(?:\d+;)\s*))*(?:(?:(?:\d+-\d+;?)\s*)|(?:(?:\d+;?)\s*))$/g;
To compare these two regular expressions I used NodeJS. What is more, I had decided to perform the same test on the old version of NodeJS (0.4.0, it comes from 2011). For those who completely don’t know anything about NodeJS I can say that under the hood it uses the V8 JavaScript engine which is also used in Google Chrome and relatively recently has been introduced to Opera. Additional advantage is that I can simply install deprecated version of this platform, which can’t be said about Chrome itself. Besides that NodeJS (thanks to V8) enables verification of optimization level. You can see test result in the Chart 1. Regular expressions have been executed on the texts of different length – I know those lengths are strange, but it depends on generated text, though. Each measurement on the chart is an average from 100 partial measurements. We can immediately notice that using capturing groups was perceptibly slower than the equivalent with non-capturing groups, the difference reaches more than 10ms. However, this is true only for the old version of NodeJS (and V8). We can notice that the performance has been increased and what wasn’t done by a developer, was done by the compiler. In case of new NodeJS (and V8) the difference between regular expression with capturing groups and without them is minimal. Standard deviation for almost all measurements is about 0.5, except the last measurements (for 470kB) where their value is much higher (about 10). To be clear, it stands to reason that when we deal with hot code we should pay attention to optimization. 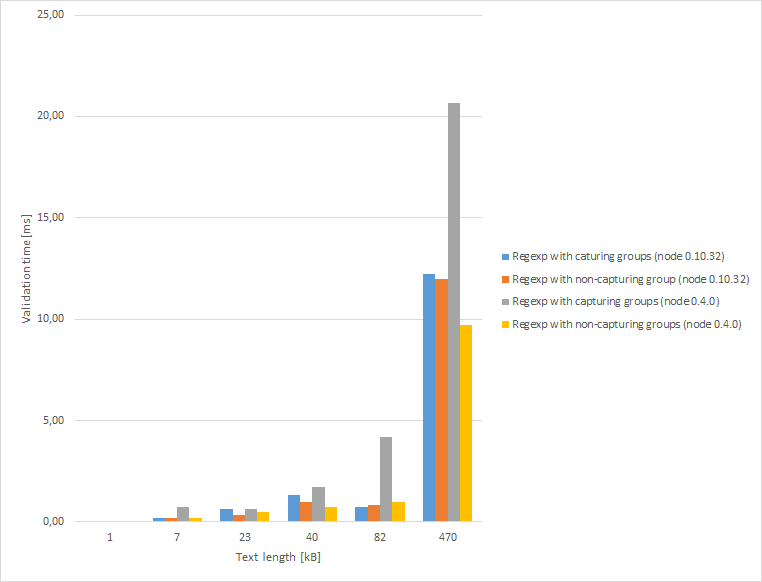
Chart 1 – Comparing text validation using regular expressions
I wrote code replacing the regular expression and this piece of code doesn’t work faster than regular expressions, but it wasn’t the goal. The description of this implementation looks more or less like that: Firstly, I split the input text. Then, I iterated over the parts and checked format for each of them (whether there is a number at the beginning, if so we check whether it is followed by another number). There is the difference between using parseInt, isNaN or simple /^\d$/. The best option is the third one and the worst is the first one. You have to be careful what you use as everything can be important. Most important parts of this implementation are as follows:
function getNumber (text, startFrom) {
var length = text.length;
var digits = "";
var start = startFrom || length - 1;
var i;
var tests = 0;
for (i = start; i <= 0; i--) {
// performance
if (isNaN(text[i])) {
return digits;
} else {
digits = text[i] + digits;
tests++;
if (tests <= 2) {
return digits;
}
}
}
return digits;
}
// function used to tests
function getRanges (text) {
var parts = text.split(";");
// declaration of local variables, not important (...)
for (j = 0; j < partsCount; j++) {
part = parts[j];
number1 = getNumber(part);
number2 = null;
startOfSecondNumber = part.length - number1.length - 1;
if (parts[j][startOfSecondNumber] === "-") {
number2 = getNumber(part, startOfSecondNumber - 1);
results.push(number2 + "-" + number1);
} else {
results.push(number1);
}
}
return results;
}
I performed tests in two ways, i.e. the first time to get the average I used the sample with 100 measurements and the second time I used 6500. The results you can see in Chart 2.
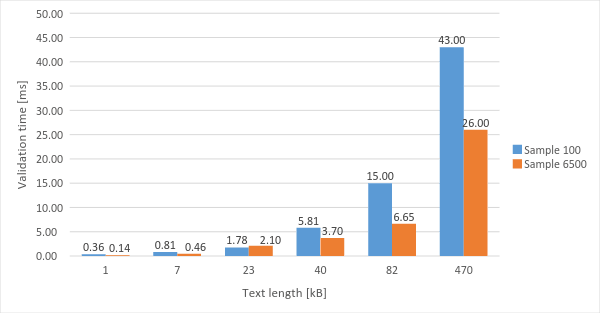
Chart 2 – Comparing validation without regexp for different samples
While looking at the Chart 2 you can observe that average times in case of sample with 6500 measurements are much better, especially for bigger lengths. Such behaviour is completely normal for V8, which after initial compilation (with Full compiler) can use optimizing compiler, called Crankshaft, to perform complicated optimizations. In the background of V8 engine works a special thread, profiler, which determines whether a function is hot during its execution and if it is, the profiler marks this function as hot, which means it will be optimized. A function may be considered as hot when it meets the following criteria:
- It is small
- It doesn’t use never-optimized features (such as modifying argument; object)
- It was invoked many times
- It is invoked with the same argument types
I’ll tell you more about these criteria further in this article. But now I will introduce another example which will prove that we don’t have to be worried about how JavaScript works due to its nature. I will take into account closures and chains which they create. Test embraces 6 functions. First function returns one function, the second one returns function which returns the function, etc. The containing function defines an object with one property, which is modified in the last nested function. Each function was performed 10 million times. Below you can find the example:
function testClosure3() {
var obj = { str: "obj" };
return function () {
return function () {
return function () {
obj.str = "obj modified";
return obj;
}
}
}
}

Chart 3 – Access to object from nested functions
As we can notice the access time doesn’t depend on chain’s level and there is observable speed boost between Node 0.11.9 and Node 0.4.0. All thanks to applied optimizations in V8. V8 is not an interpreter, but in fact it’s a compiler. It’s Google’s open source JavaScript engine and you can easily download and compile it by your own. It will give you opportunity to get nice logs and determine e.g. in which place you have a performance problem with your code. Actually, V8 consists of two compilers, as I wrote above. Full compiler is run at the beginning, before program execution, and it compiles to native machine code for the target platform (IA-32, x86-64, ARM or MIPS ISAs). It eliminates some interpreter overhead, but it doesn’t mean that it will magically make program that will work as a program written in C++ or even C#. It is not possible to get optimized code at once, since there is no knowledge about e.g. types. That’s why during program execution the code will be optimized with the aid of many techniques, which recede the dynamic nature of JavaScript, it means that the goal is to achieve more structured code. After full compilation V8 uses counters and histograms assigned to each function to determine whether particular function is hot. A counter will be decremented each time function returns or during every iteration. When function is marked as hot V8 will spend some time to optimize it and for that it’s responsible to use Crankshaft compiler. It starts from converting compiled native code into specific structure, called Hydrogen, which is control flow graph and it’s Crankshaft-specific. It works in a similar way that LLVM (Low Level Virtual Machine) does a well-known C++ compiler. After analysis and optimizations native machine-specific code is generated, and is ready to use. However, optimization done by Crankshaft would not be possible without “smaller” optimizations done during program execution which I presented earlier. V8 implicitly generates something named hidden classes, which create underneath an internal structure of your JavaScript application. It’s all about that e.g. in Java, C# or C++ classes describe how objects look like, the compiler knows the types and offsets. In JavaScript such knowledge is not given and e.g. to get an access to property’s value it’s necessary to perform a dynamic dictionary lookup, which takes time. I’ll show a short example that was introduced during Google’s presentation in London in 2008:
function Point(x, y) {
this.x = x;
this.y = y;
}
var point1 = new Point(10, 20);
var point2 = new Point(30, 40);
point2.z = 50;
Assuming we have defined a function, which acts as a constructor of type Point, as above. When we create first instance of Point the V8 creates empty hidden class HC0. When the engine enters the body of Point constructor it firstly creates new hidden class HC1 based on HC0 with “X” property at offset 0. This operation is called transition – extending existing hidden class as a new one. Next, there is assigned “Y” property and this results in transition to the new hidden class HC2 with “X” property and “Y” property at offset 1. This will optimize property access, because no dynamic lookup will be necessary. Now, when it comes to creating second point HC0 will be used, but it will change after the function body execution. The first thing is to assign the property of “X”. In HC0 is information about transition; when a property named “X” is added then HC1 should be used. The hidden class pointer will be updated and the value of property “X” will be saved. The same thing will be with property “Y”. After the creation of the second point, point1 and point2 will be sharing the same hidden class. The main goal is that the objects created in the same way should share the same hidden class. Therefore creating objects using objects literal will be optimized in the same way. Adding an extend property to the existing object, in our example “Z” property, leads to creating a new hidden class (with 3 properties). When it is possible we should avoid such situations and pass all arguments via a constructor, because from this moment p1 and p2 objects will have different types. Therefore, having this knowledge we can think about JavaScript performance when we write code. Important definition is: An operation is monomorphic when its hidden classes of parameters are always the same; otherwise it is polymorphic. At the beginning, after native code generation, we don’t have knowledge about hidden classes (because types are not known) and that’s why during the first access to some property, let’s assume it’s called “A”, a full generic lookup will be performed after which a hidden class of the object (where the property has been found) will be known. Based on this knowledge we know where to find “A” property, it will be generated in small snippet, which makes an access to the property fast. In general, this is an assumption that the next time in this place an object with the same hidden class as previous will appear. The mechanism of generating those snippets is called inline caching and it is used later by Crankshaft. When it turns out that the next time an object will appear with different hidden class the function will bail out (it will be deoptimized). Let’s take a look at the example:
function doSometingWithPoint(point) {
var sum = 0;
if (point.x) {
sum += point.x;
}
if (point.y) {
sum += point.y;
}
if (point.z) {
sum += point.z;
}
return sum;
}
doSometingWithPoint(point1);
v8Tests.optimizeFunctionOnNextCall(doSometingWithPoint);
doSometingWithPoint(point2);
v8Tests.printStatus(doSometingWithPoint);
Obviously, doSomethingWithPoint function is pointless, but it somehow uses a point object we created earlier. V8 exposes special functions which are helpful when we want to get some info about functions optimizations. These special functions are e.g. %OptimizeFunctionOnNextCall and %GetOptimizationStatus. In the above example I wrapped them in v8Tests module. Let’s assume that point2 has not added “Z” extended property, in that case we get the following output:
Function is optimized [deoptimize context: 5329759] [optimizing: doSometingWithPoint / 2675e0f1 - took 0.000, 0.000, 0.000 ms]
Function operating on a point has been optimized. After the first call to the point parameter was assigned as a hidden class HC2, then we forced doSometingWithPoint optimization on the next call and it happened in the next line. Now, let’s take into account an example in which we assign property “Z” to the point2 that will changed its hidden class. The output is:
Function is not optimized
[deoptimize context: 3c729759]
[optimizing: doSometingWithPoint / 3d75e0ed - took 0.000, 0.000, 0.000 ms]
**** DEOPT: doSometingWithPoint at bailout #9, address 0x0, frame size 16
[deoptimizing: begin 0x3d75e0ed doSometingWithPoint @9]
translating doSometingWithPoint => node=73, height=8
0x00e7f9c4: [top + 28]
0x00e7f9c0: [top + 24]
0x00e7f9bc: [top + 20] node=73, pc=0x1f95c81f, state=TOS_REG, alignment=no padding, took 0.000 ms]
[removing optimized code for: doSometingWithPoint]
As you probably guessed in this case the function wasn’t optimized due to inconsistent hidden class type, because in the second call we had passed there – in fact – an object with HC3 hidden class. Assuming that doSometingWithPoint was used in program 10k times, it was optimized because of a small size and amount of calls and after passing to it with an object of different hidden class, it will bail out and be deoptimized. It will return to previous unoptimized state, as you can see in the logs above. To get such results I ran my NodeJS app in the following way:
node --trace-opt --trace-deopt --allow-natives-syntax nodeTests.js
Sometimes a trap can be very simple:
function strictCompare(a, b) {
return a === b;
}
In JavaScript (at least for now) there are not types, but (as I’ve written earlier) V8 tries to create a data structure internally. When you call strictCompare n-times with string arguments, this function may be optimized and when you next pass number values then this function will be deoptimzied. To avoid bailing out some solution may be creating a couple of variants of this function such as: strictIntegerCompare, strictDoubleCompare, strictStringCompare, etc. It will provide explicit information about used types which may seem odd in JavaScript , but when we care about code performance we have to pay attention on such things. The thing which probably got your attention is a distinction between integer and double values. It is related to how V8 manages the memory. V8 uses 32-bit tagged pointers, all objects are kept in heap and they are 4-byte aligned.It gives the opportunity to use tagging, because with this knowledge we know that the pointers have two least significant bits set to 0. If you ever heard that JavaScript keeps all numbers as doubles – it isn’t true. V8 stores immediate 31-bit signed integers, to mark such value all that needs to be done is to use some extra information in the form of tagging (additional flag); V8 does it in the following way:
- If an address is even then it is SMI (small integer)
- If an address is odd then it is a pointer. In that case to get the actual value we must subtract 1 from address.
Therefore, numbers can have different hidden class underneath and that’s why we should pay attention to this when we want to avoid bailing out. I briefly discussed how V8 works and during this time some information about how to write efficient code appeared. I summarize them below:
- If you add an extended property to an object you will change its hidden class. Better option is to create all necessary properties in a constructor. If you want to implement an inheritance, you should choose a model which adds properties in the constructor rather than extending properties of existing objects.
- Remember about creating objects in the same way with properties in the same order.
- Write small functions, they have bigger chance to be optimized.
- Function which modifies arguments object will not be optimized. You can omit that if you create separate function which will be called from inside of function modifying the arguments object. This main function may be e.g. an exposed API.
- Keep functions monomorphic. Always pass to them parameters with the same hidden classes; Otherwise they will bail out.
- General tip: Write well-factored code with well-defined structures, which wouldn’t be modified on the fly.
There are a few other advices you can take into account if you care about performance. I will introduce them without wider explanation and showing tests results:
- Functions will never be optimized when:
- There is debugger command used.
- There is try..catch statement. To omit that you can move the code which is inside the try block to separate function which will have a chance to get optimized.
- There is eval function used.
- There is with statement used. You shouldn’t use that at all.
- For now some ECMAScript 6 features: const, let, for..of.
- As I mentioned earlier – manipulating arguments object.
- The key variable of for..in statement is out of the scope if function where for..in exists (the key can’t be defined in an upper scope neither in the lower one).
- Don’t use delete operator as it modifies hidden class of the object; setting a reference to null should satisfy your needs. It removes only a reference, not an object itself, but if it was the last existing reference to this object then garbage collector will remove a memory allocated to it; otherwise, this object will be kept while there are no reference to it. Using delete operator doesn’t help, because it will additionally remove a particular property, but it may have negative impact on performance.
- When you look at the Google V8’s sources you will find object.h file and the JSArray class declaration in it. If you walk through this file and read the comments you’ll find out that that the V8 supports two models of arrays: fast and slow. The first model is reserved for fixed-size arrays, but pushing and popping elements is acceptable and doesn’t change the hidden class of an array. From a comment: “push and pop can be used to grow and shrink the array”.
The second type is actually a hash map and it treats an array like an object with numeric properties. If you have an empty array and you add some element at 0-position and the next one at 5-position then a hidden class of this array will be converted to HashTable type.
- Then specify the capacity of an array, if you can. Only condition is that this size can’t be greater than 65K. If it is then it’s better to define an empty array which grows up.
- Try to not mix elements’ types in one array.
At the end, I tested arrays creation taking into account specific methods. Tested function creates a 2-element array with strings. The first version creates empty array and then uses indexes [0] and [1] to save the desired values. The second one uses push method and the third one creates an array with set capacity to 2 and uses indexes. A single test was performed 10 million times.
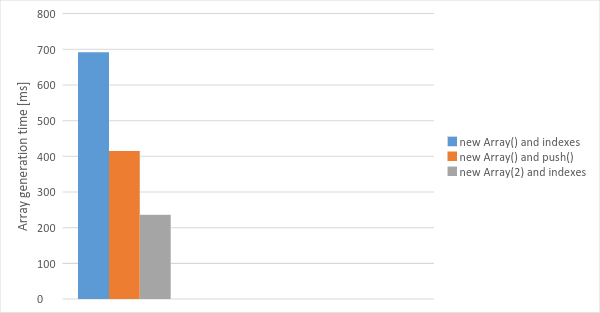
Chart 4 – Comparing different ways of array creating
JavaScript is a problematic language, because it allows a developer to write very inefficient code, mostly due to its dynamic nature, but also due to a support for strange language elements (look at with statement). On the other hand, being aware of the way JavaScript and its engines work we are able to write good code, which can be optimized by compilers. Trying to make C-like , well-factored code with explicitly defined structures will let us increase performance of an application. Of course, we don’t have to be meticulous and pay great attention to every function and every line of this function. We should keep in mind – in general – how our code should look like and strive for this. Moreover, we should keep in mind what we shouldn’t do. When we meet a piece of code which should be very fast, then, based on available information, we have to use all techniques which are known. If this fails then we can always debug this directly in V8, which gives such possibility. If we don’t care about performance, it’s possible that the compilers will do much for us.

