
- Processes, standards and quality
- Technologies
- Others
We’re not new to Jenkins. In fact, we’ve been using it quite willingly in a handful of projects in Future Processing. Mainly to help us track the built statuses and automate certain tasks.
Jenkins CI build pipeline improvements
It’s pretty much a default choice when putting continuous integration into place for java-based systems. Actually, it works just fine with other languages/tools too (there are literally hundreds of open-source plugins out there). Bamboo might be a strong competitor here, however, it has other shortcomings on its own.
Usually, it’s as easy as pie, when it comes to setting up a simple scenario – e.g. building your app including execution of unit-tests. It’s rarely the case – as the system grows, this scenario quickly becomes insufficient and needs to be refined to get a shorter feedback loop, or extended to cover several layers of the testing cycle.
Since every software project is different in a way, there is no silver-bullet Jenkins template that can be successfully applied in every possible context. Sooner or later, you’ll have to invest time in your CI process, hopefully to gain time or other qualities in the future.
Let me share with you a handful of observations and hints from our real-life enterprise project.
The problems we’ve been facing
Before I jump straight into the problems and solutions, let me present some more background about the build pipeline that we used to have in the project. The system consists of two main web-apps, several micro-services and a User Acceptance Test module, altogether spreading over 4+ GitHub repositories and a few Maven & rake projects. Because of specific requirements, we need at least 3 instances of the system up and running simultaneously to be able to test every corner-case. For the need of CI of the components, we’ve harnessed the basic Build Trigger functionality in Jenkins along with GitHub and Maven plugins. Most of the pipeline elements would be processed sequentially, some of them entangled in a confusing and asymmetric network of triggers resulting in redundant runs, etc.
It all led to the following situation:
- The build would take too long to complete, giving a very late feedback, ever increasing the time needed to get the system back to green in case of test failures,
- The dependencies between Jenkins jobs were never clear at first glance, and one had to delve deep into the configurations to make out what’s going on,
- We lacked a graphical visualization of job chains,
- All Jenkins jobs would lay in the same space with no order whatsoever,
- In some cases a failure of smoke-tests would not prevent from deploying the faulty war file to staging machines.
What have we achieved and how
- The complete build (compile and unit-test all modules & apps, run integration- and smoke tests, deploy the built artifacts to three staging machines, execute User Acceptance Tests against the set-up environment) is now taking ~30min less (from ~70min down to ~40min).Techniques that helped us get there:
- passing-the-artifact – for every deployment to the staging machines we take the artifact from the last successful build (no need to rebuild it every time),
- parallelized deployment Build Flow Plugin,
- parallelized execution of User Acceptance Tests (Build Flow Plugin),
- Transparency in job dependencies,
- no hidden triggers or actions; all explicitly stated in Build Flow Plugin scripts and only there,
- graphical job execution graphs displayed for each build (again Build Flow Plugin feature),
- A few categories of jobs: Atomic jobs, Build Chains, Sonar, UATs
- Always deploying a stable artifact,
- (<em?pass-the-artifact approach mentioned above)
- More stability, less random failures,
- refined database connection settings and socket timeout configuration,
- hardened the smoke-tests initialization process,
- Keeping a history of configuration changes for each job,
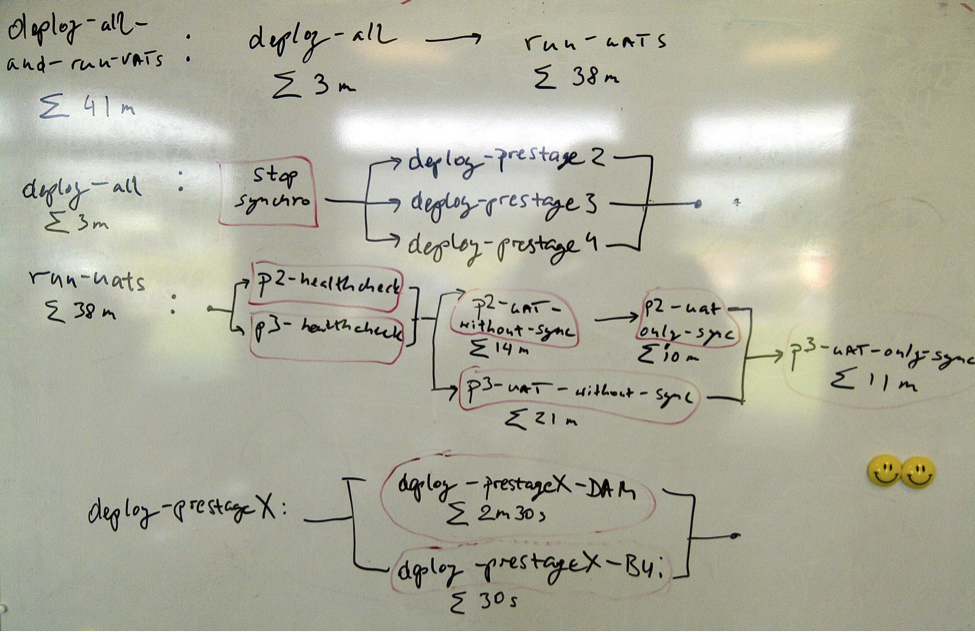
A peek into currently build pipeline
To give you a short overview of how our Jenkins build pipeline looks like now – please see the attached images. The key features:
- deploy-all: stops the synchronization between deployed instances and then deploys all the apps to all stage machines simultaneously (~2min)
- run-uats(~37m):
- Performs health-checks against the deployed apps,
- Then forks into two lines of execution:
- Run all UATs on stage2 (~11m)
- Run all non-synchronization UATs on stage3 (~25m)
- After both lines are completed:
- Run only synchronization UATs on stage3 (~11m); we don’t want synchronization UATs running in parallel on stage2 and stage3, as it’s problematic.

Summary
To sum up, we’ve leveraged the power of BuildFlow plugin to help organize our build pipeline. It offers two killer features, which we found just perfect for our needs:
- Possibility for configuring jobs with a simple scripting language, allowing e.g. to trigger other jobs in parallel. At the beginning, we were a bit sceptical about scripting the build with a custom DSL, but in the end it worked out very conveniently.
ignore(FAILURE) {
build("stop-synchro-on-all-prestages")
}
parallel (
{ build("deploy-prestage2") },
{ build("deploy-prestage3") },
{ build("deploy-prestage4") }
)- Graphical visualization of the flow for every BuildFlow-based job, along with results of the dependent jobs and their execution time:
We’ve also followed Kohsuke Kawaguchi’s advice – to pass the artifact whenever possible to avoid unnecessary compilation overhead. He suggested trying Promoted Builds Plugin and Copy Artifact Plugin but they didn’t quite fit into our deployment process, therefore we came up with a custom bash script to figure out and reuse the last successfully built artefact from Jenkins.
Still after all these refinements, 40 minutes seems to be quite a long time to get a full feedback. In fact, we get the preliminary (and usually sufficient) information after a few minutes, simply after running smoke tests. Well, there’s still room for further improvements in general, but cutting down the time nearly in half, without any adjustments to the testing infrastructure, Jenkins workers, or application code-base sounds really encouraging!