
Database Versioning
- Processes, standards and quality
- Technologies
- Others
Motivation:
Let’s imagine that we are working in a project where several other people work as well. Let’s also imagine it is a project in which a database plays a crucial role. During a single iteration, two developers work on different functionalities which make modifications in identical parts of the database schema.
You should already feel the fear having read the above. Let’s increase the fear level – let’s say that changes to the database may also be introduced by third parties including clients or their subcontractors. In this case I can tell, from my own experience, that it’s just a matter of time until the Earth shakes and all the filth will come out of its depths.
The below are the symptoms that something is wrong:
- The newly introduced change has spoiled something and it should be removed.
- Someone has changed something somewhere and forgot to mention that.
- Two developers have simultaneously introduced changes so consequently those made by the first one have been replaced.
- The stored procedure has accidentally been deleted from a database.
- A series of changes in stored procedure result in the procedure working too slowly.
Those are only a few of symptoms that occur most often (in my opinion). On the other hand, if you’re looking for a cure-all for the above problems, this article is for you.
How did it look like in the past:
While working in Future Processing, I have come across many ways of managing a database and deploying changes to multiple various environments. Some of them used our internal solutions; whereas the others preferred ready to use solutions such as Liquibase.
In one of the projects of that time, the database was rather complicated and is was modified quite often, not only by us but also by our client, without letting us know. Before a given change was introduced to the production environment, it had to be tested. To do so, we have used testing and pre-production environments. To be polite, I’m not going to mention the development environment.
What we have learnt:
Every developer knows that before something is committed, it has to be tested thoroughly or the developer will be condemned forever.
TSQL is treated like any other code. It goes through the Code Review procedure due to which we have created certain coding standards.
So let’s see how it looks in our project and which tools make our problems disappear.
How has it been improved:
Database code (TSQL) is stored in the SQL Server Database Project inside the GIT repository. It is a component of the SQL Server Data Tools set (which I have mentioned in the previous articles) and it enables having full control over the development of our software and, more precisely, over a database structure and the whole deployment process. Together with GIT it opens up many possibilities. Of course, it’s not a flawless solution; however, a lot has been improved compared to its previous versions. Some features have been deleted and replaced with better ones. Its predecessor really tired me out.
What is better in 2012 version:
- File structure was simplified.
- Visual table designer looks betters and works betters.
- Better build and deploy options, easily integrated with continues integration tools.
SQL Server Databases Project:
I will focus on the database project only in this article.
The database project allows a user to design a database from scratches, as well as to work on an already existing solution.
The first step to start working is to install the package. Then we should create a new project using the template that we have just installed. (Installed -> Templates -> Other Languages -> SQL Server).
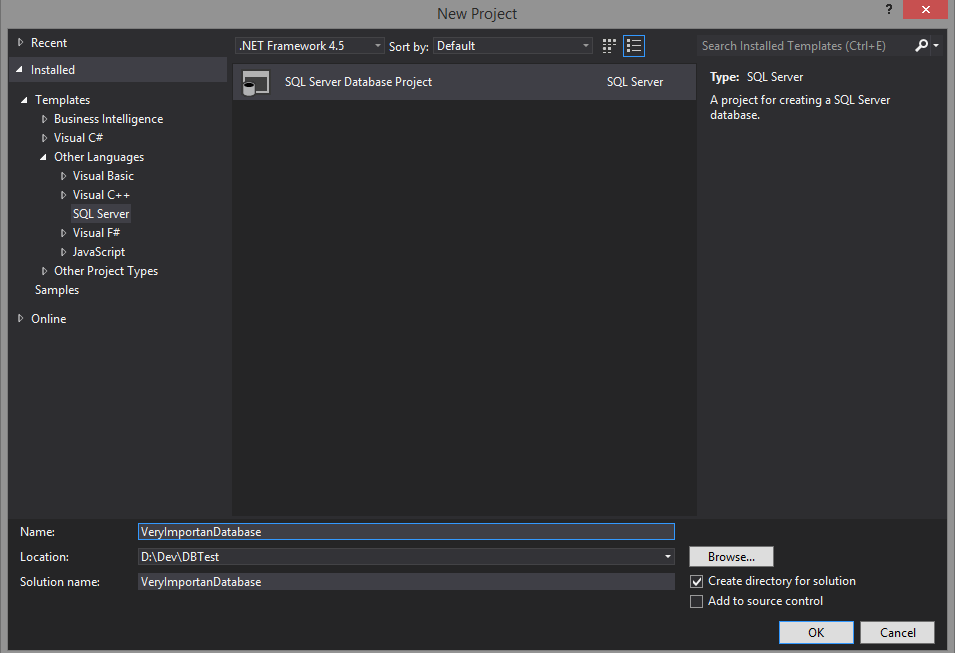
To proceed, right click the newly created project and select the option 'Import’ in the upper part of the context menu. We have several possible ways of importing the database structure:
- Sql file.
- Database indicated with connection string.
- Dacpac file.
In the previous version, there were two separate types of projects: SQL Server Database Project and SQL Server Project. At this moment, we have only one type of project at our disposal – but it joins the functionalities of above mentioned projects. While the database structure is being imported, we need to decide whether we are interested only in database objects or in server objects such as logins, roles, permissions etc. too. If you’d like to define permissions or deploy users, you also need to additionally import logins from the server. Otherwise, you will see an error.
To continue, let’s import the structure of a simple database that contains 2 tables (note that they are not empty and that they contain extremely crucial business data which we do not want to lose).
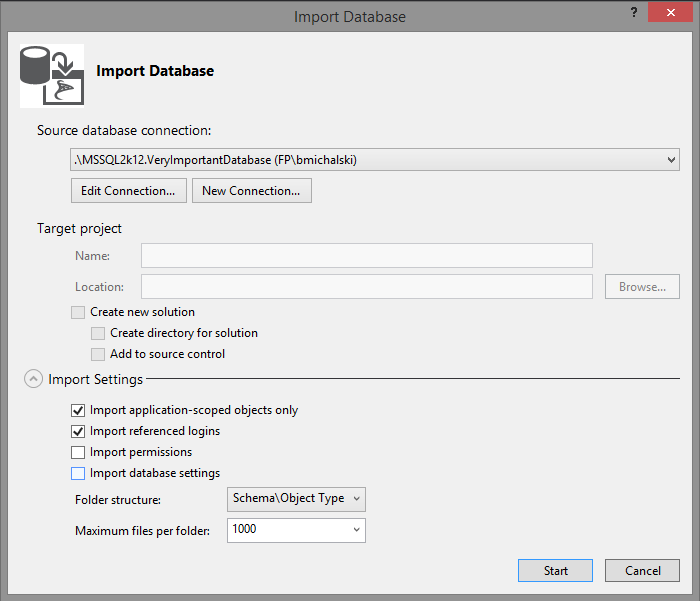
The 'Import Settings’ section can be found in the lower part of the window. This is also where you can choose whether to import logins and permissions.
In the Solution Explorer window, you can notice a simple structure of catalogues which map themselves into schemas in a database and into folder named Security which contains users, permissions and logins. The Security folder is not mandatory and so it may not appear unless relevant options are selected during the import.
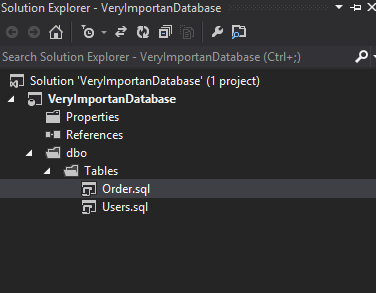
In every schema folder we are able to find subfolders which correspond to tables, views and procedures in that schema.
Double clicking on any object we can access the TSQL code of a given object and in some cases, the designer. In case of tables, we can easily select a lot of things using a designer, for example, we can add indices, constraints or even add a column. Personally, I am rather old fashioned and I prefer doing all of this stuff from the TSQL level.
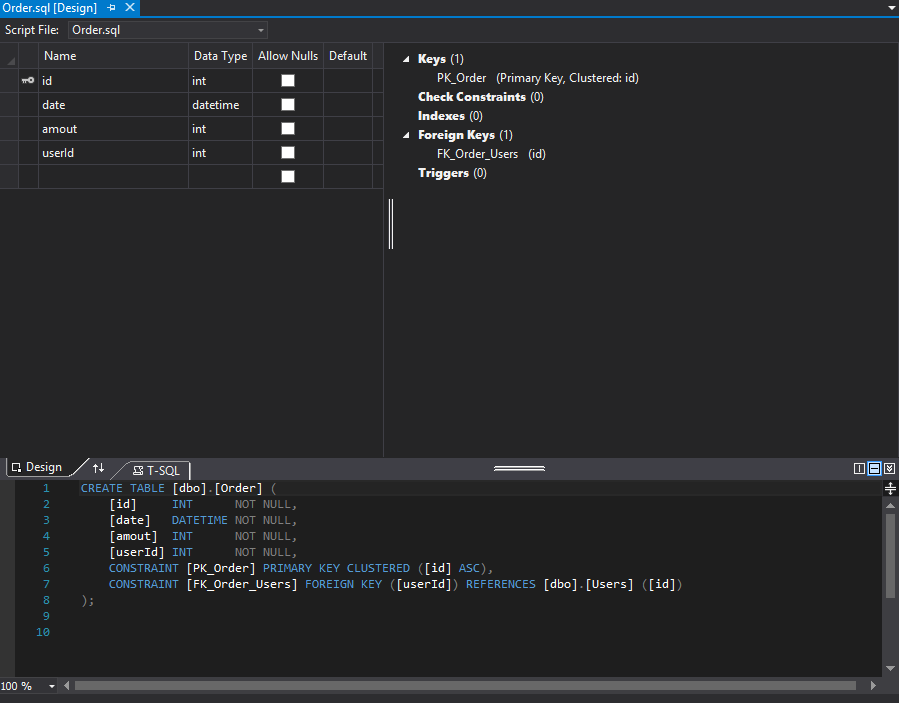
TSQL is a very powerful tool and to make it easier to use we have both intelisense and a validator. Those tools verify whether the solution that we are working on is correct in terms of syntax.
Importing changes:
Certainly, the majority of database developers (followers of great TSQLulhu) are used to tools such as SQL Server Management Studio and to make changes in their local database using scripts. The SQL Server Database Project tries to meet their needs as well. They don’t have to migrate their changes manually. When their work is done, they may import changes to the database project in a simple way, and then commit them to the global VCS repository.
Selecting the Schema Compare option from the context menu of our database project, we can compare the current state of a database project with any other database project. Actually, we can compare any two database structures using this method. There are several options of comparing those, but in our case we will select comparison using tables and views.

In the screen below we can observe the effect of such comparison. In the upper part of the window we can see what has changed. Some elements have been added (Add Section), some changed (Changed Section) and the others deleted (Deleted Section). In the lower part we can observe how the version of TSQL code has changed. In the screen we can also notice that:
- Two tables have been changed: Orders and Users.
- A new view has been added: UsersWithOrders.
To see the details of a change, click on it. In this case, IDENTITY has been added to the column of an upper key.
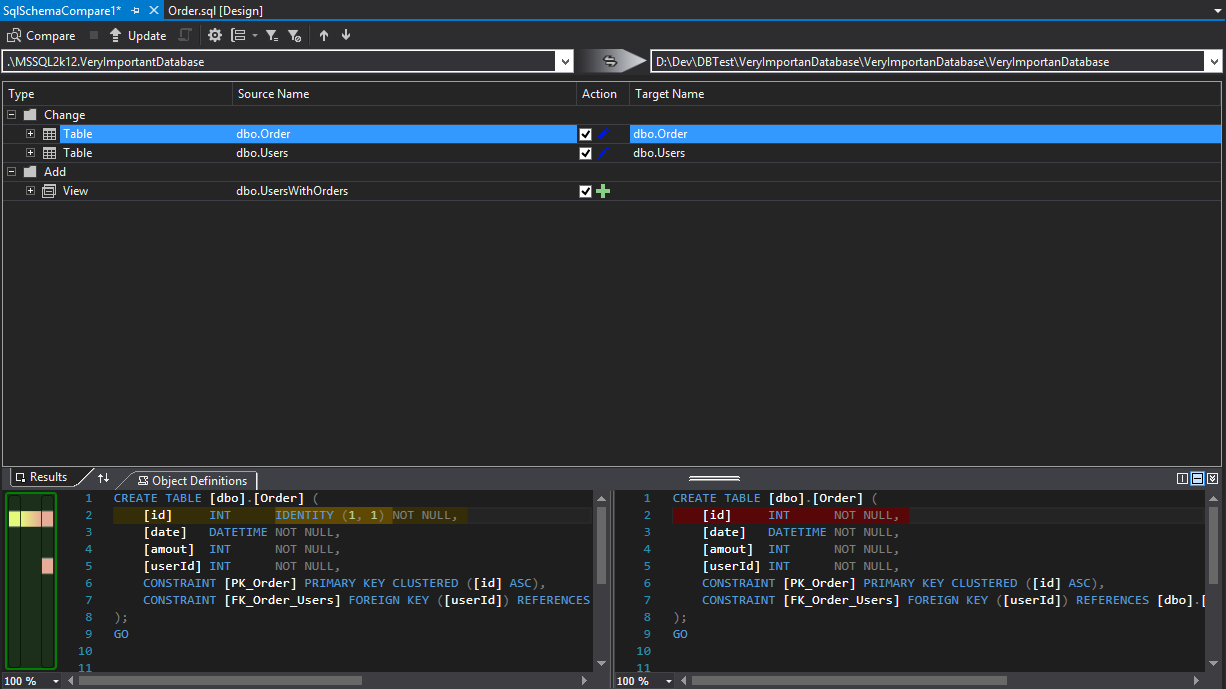
In the ADD section, we can see that a new view has also been created. We can select only those changes that we want to import to the project and then press the Update button.
Deployment:
Deployment is a very important element of the package. It can be performed in several ways:
- Generating the SQL script that will be run manually on a database. Updating the database schema from the Visual Studio or from a command line using MSBuild, if preferred. The second methods may be later used to configure a Build Server, which will automatically deploy the changes after the commit, or on demand.
- Generating the dacpac file. Dacpac file is a special type of a snapshot of a database structure. It is strongly related to the Data-Tier Application functionality.
A dacpac can also be deployed using the SSMS Wizard, activated either from the SQL Server Management Studio level or using SQLPackage.exe tool which can also be used in the automation process. Yes, process automation is a very important part of our job.
Dacpac can also be deployed using a Compare Schema screen. This screen gives us a lot of control over the system. We can deploy only some of the changes, e.g. views. Unfortunately, when generating a snapshot of a project (a dacpac), we won’t be able to choose selectively which changes will be deployed. We have to deploy all of them without a single exception.
Additionally, we can create a database from scratch without any data whatsoever or deploy changes without losing all the data that it contains. As I mentioned before, the existing data are very important and any possible data loss or corruption needs to be protected against. Thus, wizard will suggest if there is any possibility of losing data or of existence of any other conflicts that could cause any problems. That way we can decide to abort the process without destroying anything.
To make the process easier, we can define the profile files, which would point us to the destination of a deployment and additionally the options of the deployment. Having selected the Publish option from the project context menu, the following window will appear:
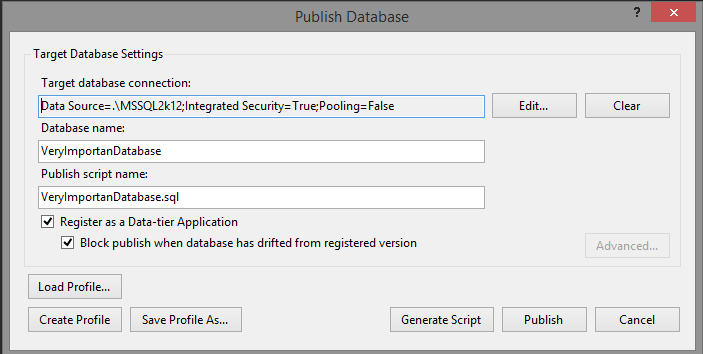
We can deploy the changes on any server we can select at once, but also we can decide to generate the script containing the necessary changes.
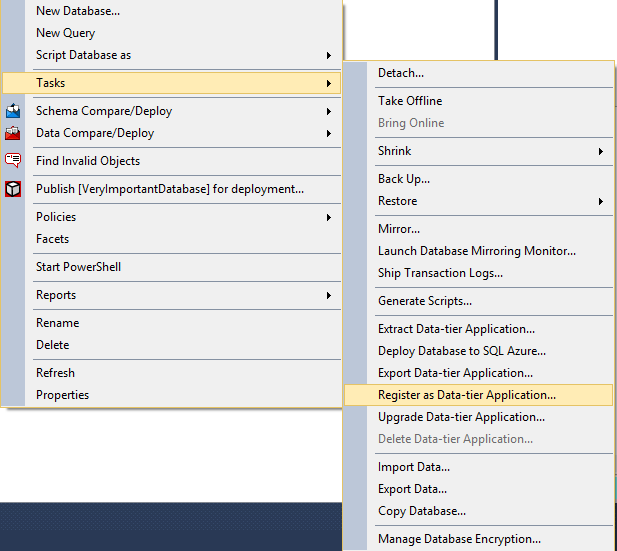
Another option that we can select during the deployment is the Register as a Data-tier Application.
After the database has been registered, a snapshot of the database structure will be created. Whenever an attempt of a deployment of another version is made, the changes are verified against the previous version and according to the differences new changes are made. Then the version number stored in msdb table will increase. If we tried to deploy a file with a lower version number, the application would not allow that.
Conclusion:
I wasn’t really sold on the previous versions of this product. However, the latest version is mature enough to be ready to be used.
If some functionality does not satisfy us or are not sufficient enough for our needs, we can always use the .NET platform and adapt it to our particular needs. Together with GIT, those tools give us full control over the process of changes in a database. We can work on the same set of tables with a few people and while committing we can stop worrying of data corruption or irrecoverable losses. If appropriate profiles are created, the changes can be introduced to multiple environments simultaneously, both manually and automatically.
As I mentioned, this particular solution is not flawless but it has helped us to gain control over the abyss called casually 'a database’.
