
- Processes, standards and quality
- Technologies
- Others
CovTrace to w założeniu aplikacja do monitorowania oraz przeciwdziałania rozpowszechnianiu się epidemii Covid-19 z wykorzystaniem Bluetooth i technologii mobilnych.
W założeniu platforma miała składać się z dwóch głównych komponentów:
- Aplikacja mobilna (na platformy Android oraz iOS) dla użytkowników - dostępna dla każdego obywatela posiadającego smartfona z wyżej wymienionym systemem operacyjnym,
- Panel zarządzający - aplikacja webowa służąca do zarządzania przypadkami zarażeń, zgłaszania nowych przypadków oraz ich monitorowania.
– Moduł odpowiedzialny za przetwarzanie danych – match’owanie danych z tel. z danymi o zidentyfikowanych, potwierdzonych przypadkach zarażenia.
Poniższe opracowanie przedstawia wyniki pracy na PoC dla modułu przetwarzania danych.
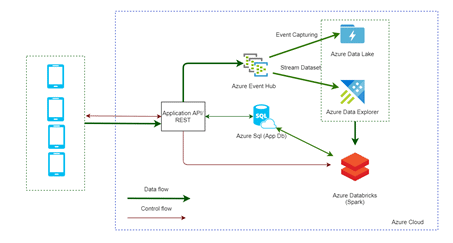
Poniższy diagram prezentuje ogólną architekturę systemu ze szczególnym uwzględnieniem modułu odpowiedzialnego za przetwarzanie danych.
Dane przesyłane z aplikacji mobilnej przesyłane są do dedykowanego endpoint (Rest API), który zapisuje dane telemetryczne do Azure Event Hub (który pełni rolę bufora). Dane z Azure Event Hub:
- są zapisywane do Azure Data Lake Storage (opcja numer 1),
- są zapisywane w usłudze Azure Data Explorer (opcja numer 2).
Samo przetwarzanie danych (match’owanie danych z tel. z danymi o zidentyfikowanych, potwierdzonych przypadkach zarażenia, baza App Db), w przypadku opcji nr 1 odbywa się na Sparku, w przypadku opcji nr 2 bezpośrednio na Azure Data Explorer. W ramach PoC zrealizowano rozwiązanie (częściowe) z opcją numer 1 i 2.
Symulator danych
W ramach PoC wykorzystano symulator danych (podobny do tego https://github.com/FP-DataSolutions/AzureBigDataWorkshops/tree/master/SweetMachineSimulator), który przesyła dane bezpośrednio do Azure Event Hub.
Format danych (z symulatora):
public class PhoneContact
{
public string OwnerPhoneNumber { get; set; }
public string ConnectedPhoneNumber { get; set; }
public DateTime ConnectedDate { get; set; }
public long ContactLatidude { get; set; }
public long ContatctLongitude { get; set; }
public long ContactTime { get; set; } //sec
} Zapis danych w Azure Data Lake Storage
Jako magazyn na dane (w przypadku opcji nr 1) został wybrany Azure Data Lake Storage Gen2. Zapis danych z Azure Event Hub zrealizowany został z wykorzystaniem mechanizmu Azure Event Hub Capture (https://docs.microsoft.com/en-us/azure/event-hubs/event-hubs-capture-overview), który pozwala na zapis danych z Event Hub na storage w formacie Avro. Dla PoC Event HUb został skonfigurowany w następujący sposób:
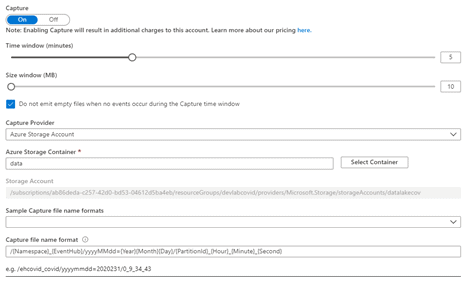
Szczególną uwagę należy zwrócić na konfigurację “Capture file name format”. Istotne, aby wybrać metodę partycjonowania danych, tak aby można było potem efektywnie przetwarzać dane na Sparku.
W przykładowym rozwiązaniu został wybrany mechanizm partycjonowania w oparciu o datę – klucz yyyyMMdd i wartość {Year}{Month}{Day}.
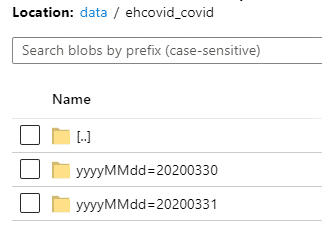
oraz plików dla konfiguracji /{Namespace}{EventHub}/yyyyMMdd={Year}{Month}{Day}/{PartitionId}{Hour}{Minute}{Second}

Zaletą takiego rozwiązania jest jego prostota (nie potrzeba żadnego dodatkowego kodu do zapisu danych). Wadą – dodatkowe koszty związane z mechanizmem Event Capture.
Zapis danych w Azure Data Explorer
Azure Data Explorer to skalowalna usługa do eksploracji danych (w szczególności danych telemetrycznych) (https://docs.microsoft.com/en-us/azure/data-explorer/).
Ładowanie danych oparte zostało o mechanizm Data ingestion – wbudowaną funkcję Azure Data Explorera, pozwalającą na automatyczne ładowanie danych m.in z Azure Event Hub.
Po stworzeniu klastra oraz bazy danych została stworzona tabela do przechowywania danych:
.create table PhoneContact ( OwnerPhoneNumber :string,
ConnectedPhoneNumber :string,
ConnectedDate: datetime,
ContactLatidude : long,
ContactLongitude: long,
ContactTime:long); oraz mapping odpowiedzialny za zmapowanie danych z komunikatu do wierszy w tabeli:
.create table PhoneContact ingestion json mapping 'PhoneContactMapping'
'[{"column":"OwnerPhoneNumber","path":"$.OwnerPhoneNumber","datatype":"string"},
{"column":"ConnectedPhoneNumber","path":"$.ConnectedPhoneNumber","datatype":"string"},
{"column":"ConnectedDate","path":"$.ConnectedDate","datatype":"datetime"},
{"column":"ContactLatidude","path":"$.ContactLatidude","datatype":"long"},
{"column":"ContactLongitude","path":"$.ContatctLongitude","datatype":"long"},
{"column":"ContactTime","path":"$.ContactTime","datatype":"long"}]' Po przygotowaniu tabeli i mappingu sama konfiguracja ładowania sprowadza się do stworzenia Data Ingestion:
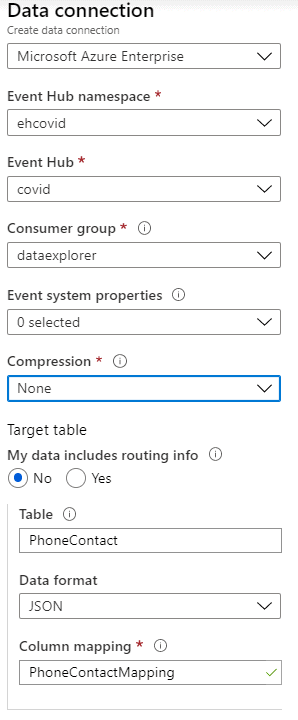
Istotne jest, aby wcześniej stworzyć dedykowaną Customer group na Azure Event Hub.
Opóźnienie przy ładowaniu danych z Azure Event Hub wynosi ok. 5 min.
Załadowane dane (zapytanie w KQL):

Ponownie, zaletą takiego rozwiązania jest jego prostota (żadnego dodatkowego kodu do zapisu danych), wadą dodatkowe koszty związane z utrzymaniem klastra Azure Data Explorer.
Przetwarzanie danych Azure Data Explorer
Przetwarzanie danych w tym match’owanie danych z tel. z danymi o zidentyfikowanych, potwierdzonych przypadkach zarażenia, w przypadku Azure Data Explorera może być zrealizowane w oparciu o zapytanie w języku KQL. Poniżej przykład takiego zapytania:
let x =
PhoneContact | where OwnerPhoneNumber in ('Phone54','Phone39','Phone56') and ConnectedDate > todatetime('2020-03-30')
| project ConnectedPhoneNumber, OwnerPhoneNumber|distinct OwnerPhoneNumber, ConnectedPhoneNumber | project l = 'Level 1',OwnerPhoneNumber,ConnectedPhoneNumber ;
let x1 = x| project ConnectedPhoneNumber;
let y=
PhoneContact| where OwnerPhoneNumber in (x1 ) and ConnectedDate > todatetime('2020-03-30')
| project ConnectedPhoneNumber, OwnerPhoneNumber|distinct OwnerPhoneNumber,ConnectedPhoneNumber | project l = 'Level 2',OwnerPhoneNumber,ConnectedPhoneNumber ;
let y1 = y| project ConnectedPhoneNumber;
let z= PhoneContact| where OwnerPhoneNumber in (y1 ) and ConnectedDate > todatetime('2020-03-30')
| project ConnectedPhoneNumber,OwnerPhoneNumber|distinct OwnerPhoneNumber,ConnectedPhoneNumber | project l = 'Level 3',OwnerPhoneNumber,ConnectedPhoneNumber ;
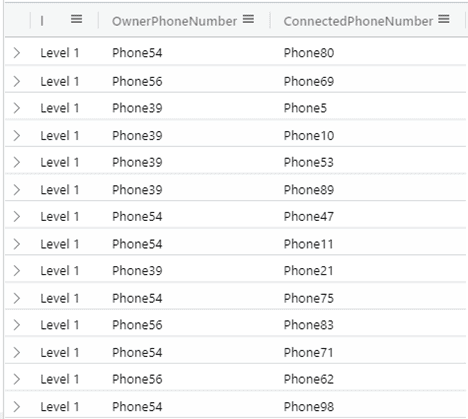
x| union y|union z Powyższe zapytanie zwraca informacje o kontakcie z osobami posiadającymi tel. 'Phone54','Phone39','Phone56' na poziomie:
– Level 1 – bezpośredni kontakt
– Level 2- pośredni kontakt poprzez osoby z bezpośredniego kontaktu
– Level 3 – pośredni kontakt poprzez osoby z pośredniego kontaktu Level2
Dostęp do klastra Data Explorer możliwy jest za pomocą driver SQL, a kod KQL wykonywany jest za pośrednictwem procedury sp_execute_kql, tak więc takie zapytanie może być wykonane bezpośrednio z aplikacji po załadowaniu danych o zakażeniach.
var csb = new SqlConnectionStringBuilder
{
InitialCatalog = "covid",
Authentication = SqlAuthenticationMethod.ActiveDirectoryIntegrated,
DataSource = "delab.northeurope.kusto.windows.net"
};
using (var connection = new SqlConnection(csb.ToString()))
{
connection.Open();
System.Console.WriteLine("KQL EXAMPLE");
using (var command = new SqlCommand("sp_execute_kql", connection))
{
command.CommandType = CommandType.StoredProcedure;
var query = new SqlParameter("@kql_query", SqlDbType.NVarChar);
command.Parameters.Add(query);
var parameter = new SqlParameter("myLimit", SqlDbType.Int);
command.Parameters.Add(parameter);
query.Value = "PhoneContact | take myLimit";
parameter.Value = 3;
using (var reader = command.ExecuteReader())
{
while (reader.Read())
{
for (int i = 0; i < reader.FieldCount; i++)
{
System.Console.Write("{0}|", reader[i]);
}
System.Console.WriteLine();
}
}
}
} Przetwarzanie danych składowanych w Azure Data Lake Storage
Przetwarzanie danych składowanych w postaci plików w usłudze Azure Data Lake Storage odbywa się za pomocą Spark (Azure Databricks), który byłby uruchamiany na żądanie np. po pobraniu danych o zakażeniach. Aby to osiągnąć, należy wykonać klika operacji:
- stworzyć dedykowany Service Principala i nadać dostęp do Azure Data Lake Storage (oraz kontenera z danymi),
- zamontować Azure Data Lake, tak aby był dostępny w Azure DataBricks – można do tego użyć poniższego skrypu (operacja jednorazowa):
configs = {"fs.azure.account.auth.type": "OAuth",
"fs.azure.account.oauth.provider.type": "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider",
"fs.azure.account.oauth2.client.id": "{ClientId}",
"fs.azure.account.oauth2.client.secret":"{Key}",
"fs.azure.account.oauth2.client.endpoint": "https://login.microsoftonline.com/{DirectoryId}/oauth2/token"}
dbutils.fs.mount(
source = "abfss://data@datalakecov.dfs.core.windows.net/",
mount_point = "/mnt/data",
extra_configs = configs) - zmapować dane telemetryczne na tabele (format Avro):
DROP TABLE IF EXISTS PhoneContacts;
CREATE TABLE PhoneContacts
(
SequenceNumber BIGINT,
Offset STRING,
EnqueuedTimeUtc STRING,
SystemProperties map<string,struct<member0:bigint,member1:double,member2:string,member3:binary>>,
Properties map<string,struct<member0:bigint,member1:double,member2:string,member3:binary>>,
Body binary,
yyyyMMdd INT
)
USING avro
PARTITIONED BY(yyyyMMdd)
OPTIONS (path "/mnt/data/ehcovid_covid/",
timestamp.formats 'yyyyMMdd') - stworzyć notebooka odpowiedzialnego za przetwarzanie. Powinien on zawierać:
- odświeżenie informacji o partycjach
– MSCK REPAIR TABLE PhoneContactsMSCK REPAIR TABLE PhoneContacts - ekstrahować dane telemetryczne z formatu Avro (kolumna Body z tabeli
PhoneContacts) dla danego przedziału czasowego (yyyyMdd -partycjowanie danych)
%python
df = spark.sql("SELECT (CAST(Body AS string)) FROM PhoneContacts WHERE yyyyMMdd >=20200130 ").rdd.map(lambda x:x[0])
spark.read.json(df).createOrReplaceTempView('CurrentData') 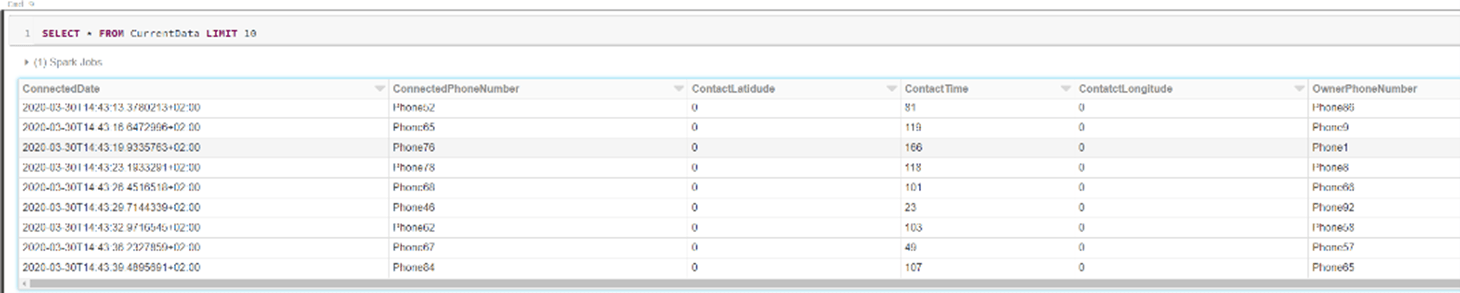
- match’ować dane z tel. z danymi o zidentyfikowanych, potwierdzonych przypadkach zarażenia (w poniższym przykładzie użytkownik tel. Phone39, ale te dane mogą być przekazane poprzez parametry lub join z tabelka z App Db (Sql Server))
WITH Level0 AS
(
SELECT '0' AS Level, OwnerPhoneNumber,ConnectedPhoneNumber FROM CurrentData WHERE OwnerPhoneNumber IN ('Phone39')
),
Level1 AS
(
SELECT '1' AS Level, OwnerPhoneNumber,ConnectedPhoneNumber FROM CurrentData WHERE OwnerPhoneNumber IN
(SELECT ConnectedPhoneNumber FROM Level0)
),
Level2 AS
(
SELECT '2' AS Level, OwnerPhoneNumber,ConnectedPhoneNumber FROM CurrentData WHERE OwnerPhoneNumber IN
(SELECT ConnectedPhoneNumber FROM Level1)
),
Result AS
(
SELECT Level,OwnerPhoneNumber,ConnectedPhoneNumber FROM Level0
UNION
SELECT Level, OwnerPhoneNumber,ConnectedPhoneNumber FROM Level1
UNION
SELECT Level, OwnerPhoneNumber,ConnectedPhoneNumber FROM Level2
)
SELECT * FROM Result 
- zapisać wyniki np. do bazy SQL.
- stworzyć joba do uruchamiania na żądania (używając wcześniej stworzonego notebooka)
– wygenerować token dostępowy - uruchamić joba na żądanie (stawianie klastra Spark na żądanie) za pomocą Rest API (https://docs.databricks.com/dev-tools/api/index.html)
POST https://northeurope.azuredatabricks.net/api/2.0/jobs/run-now
Authentication Token: {Token}
Body: Identyfikator stworzonego joba
{
"job_id": 1
} Podsumowanie
Przedstawione rozwiązania mają charakter poglądowy, ale sprawdzają w praktyce możliwość realizacji projektu w oparciu o przedstawioną architekturę. Zarówno podejście oparte o Azure Data Explorera, jak i Azure Databricks pozwalają na stworzenie skalowalnego rozwiązania do przetwarzania setek terabajtów danych. Rozwiązanie oparte o Spark aktualnie wydaje się bardziej atrakcyjne cenowo, jednak jest bardziej złożone. Sam PoC – jego praktyczna realizacja zajęła ok. 4h oraz dodatkowo 2-3h na przygotowanie symulatora.
Poniżej link do architektury podobnego rozwiązania stworzonej przez Clouderę: https://blog.cloudera.com/an-architecture-for-secure-covid-19-contact-tracing/

