
How to build a fault tolerant system?
- Processes, standards and quality
- Technologies
- Others
In many applications, where computers are used, outages or malfunctions can be expensive, or even disastrous. In that case, the system must handle the failures, but such systems are hardly ever perfect . This article presents briefly the situations that might occur to any computer system as well as fail-safes that can help it to continue working to a level of acceptance in the event of a failure of some of its components.
If anything can go wrong, it will.
Murphy’s first law
There are countless ways in which a system can fail. To make it a fault tolerant, we need to identify potential failures, which a system might encounter, and design counteractions. Each failure’s frequency and impact on the system need to be estimated to decide which one a system should tolerate. Here are just a few examples of potential issues to think of:
- program experiences an unrecoverable error and crash (unhandled exceptions, expired certificates, memory leaks)
- component becomes unavailable (power outage, loss of connectivity)
- data corruption or loss (hardware failure, malicious attack)
- security (a component is compromised)
- performance (an increased latency, traffic, demand)
Most of the typical failures can be divided into two categories:
- fail – stop behaviours (e.g. server shuts down, loss of connectivity)
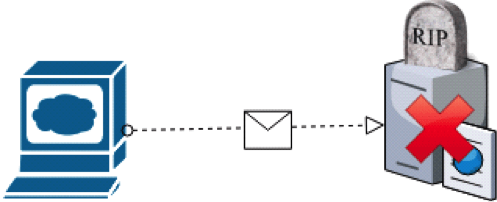
node shuts down presenting fail-stop behaviour
- byzantine behaviours (e.g. data corruption or manipulation)
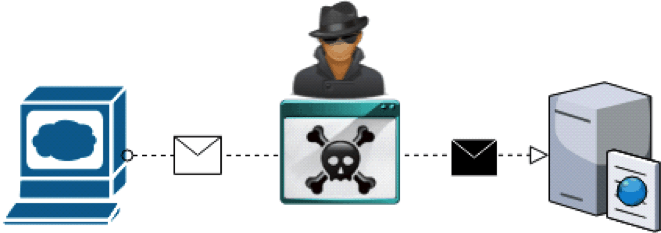
cracker amend message using man-in-the-middle attack presents byzantine behaviour
Fail-stop behaviours
Fail-stop failures are relatively easy to deal with. Here are a couple of basic strategies:
Checkpoint strategy
- Conditions:
- hardware is still working
- a consistent copy of a system’s state is available (backup)
- Action: restart a server and load the last good version of the system
- Downsides:
- a component is unavailable for a time of reboot
- there is a chance that reboot won’t help
- a component may end up in an endless crash loop
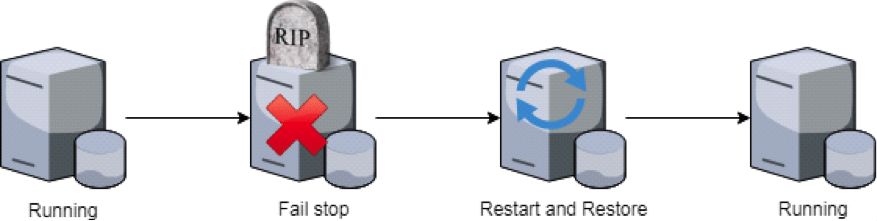
checkpoint strategy flow
Replicate state and failover
- Condition: there are valid state’s backups and redundant hardware available
- Action: start a second instance of the system and switch the traffic to it
- Downside: requires a spare hardware, which would possibly linger away for most of the time
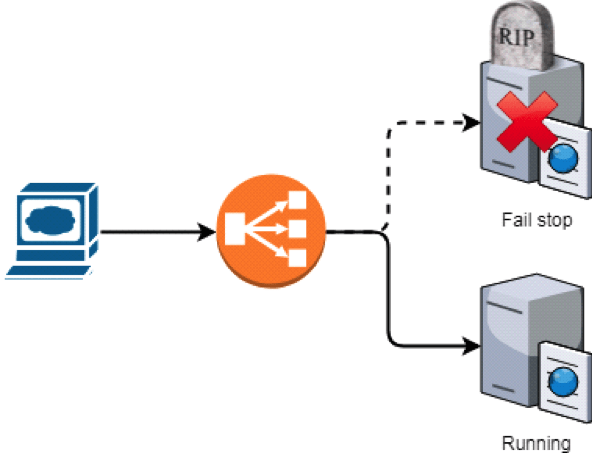
new node takes over traffic in case of other’s fail-stop behaviour
Byzantine failures
Byzantine failures are situations, where a component starts to work in an incorrect, but the seemingly valid way (e.g. data gets corrupted) – possibly due to faulted hardware (a flipped bit) or malicious attack. Reliable computer systems must handle malfunctioning components that give conflicting information to different parts of the system. Here are a couple of basic solutions:
Turn byzantine into fail-stop behaviour
- Action: use checksums, assertions or timeouts. If verification fails, the system should automatically stop and recover – hopefully in a better state
- Downsides: same as in the Fail-stop strategies
- Example: internet routers drop corrupted packets

node shuts itself to prevent wrong data from being processed
Fix corrupted data in runtime
- Action: use error detection and correction algorithms
- Downside: performance impact, because the system must use its computing power to verify data at every processing step
- Example: CRC, ARQ, ECC
Each solution to byzantine failures has its disadvantages, but they seem to outweigh the alternative, which is having corrupted data in a system. Unfortunately, there may be no solution to byzantine failure where all data is stored and processed by a single process.
Distributed systems
Another way to handle failures is to design a distributed system, but with it, things get more complicated. A distributed system is the one where a state and processing are shared by multiple computers – unlike a centralized system, where everything is stored in a single piece of hardware – that appears to a user as a single coherent system. Distributed systems can be found everywhere. Here are just a few examples:
- Domain Name System (DNS)
- Content Delivery Network (CDN)
- Phone networks (landline and cellular)
- Traffic control networks (lights, train, airplanes)
- Cryptocurrencies (Bitcoin, Ethereum)
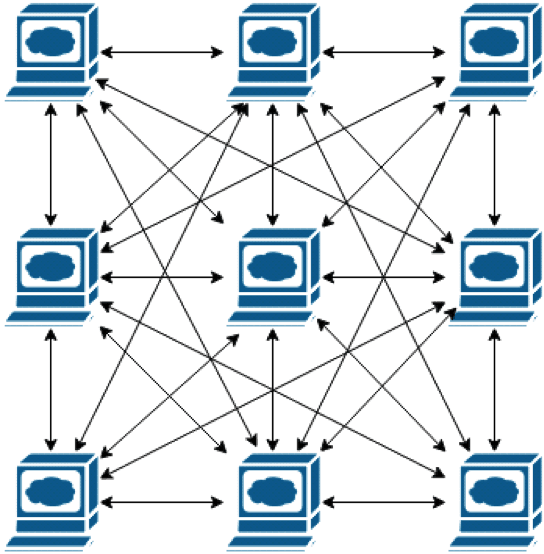
example of a distributed system with fully connected nodes
Usually, distributed systems are designed to achieve some non-functional requirements like:
- reliability – elimination of a single point of failure by using redundant nodes which take over workload in the case a node presents a fail-stop behaviour
- performance – latency reduction by placing nodes closer to clients
- scaling – ability to tune a system’s computing capacity according to the current demand by juggling with the amount of the available hardware in a system
While distributed systems may help to tolerate some of the typical failures of centralized systems, they increase complexity of a solution and comes with their own set of problems such as:
- network partition
- state consistency
Network partition
Network partition happens when some of the nodes of a distributed system lose connectivity but continue to run independently and end up in two or more disjoint clusters. In such a case, the state of the system might diverge because each cluster continues to change its own state but fails to synchronize with others. There are two common solutions:
- allow clusters to continue working independently
- Action: once nodes regain connectivity, merge their states
- Advantage: no performance impact because all nodes are available and can respond to traffic
- Downsides:
- clients may receive outdated data
- by using different clusters, clients can make conflicting changes (e.g. „double spending”, a situation where a disposable resource is consumed more than once)
- Applications:
- systems with an incremental-only (immutable) state
- systems with a read-only state (a consumer-based processing)
- suspend the work of smaller clusters
- Action: redirect traffic to the only working single cluster and once nodes regain connectivity, propagate state and resume the work of reconnected nodes
- Advantages:
- the client always receives up-to-date data
- a state consistency is maintained
- Downsides:
- the system has decreased availability and performance because requests cannot be processed by disconnected nodes
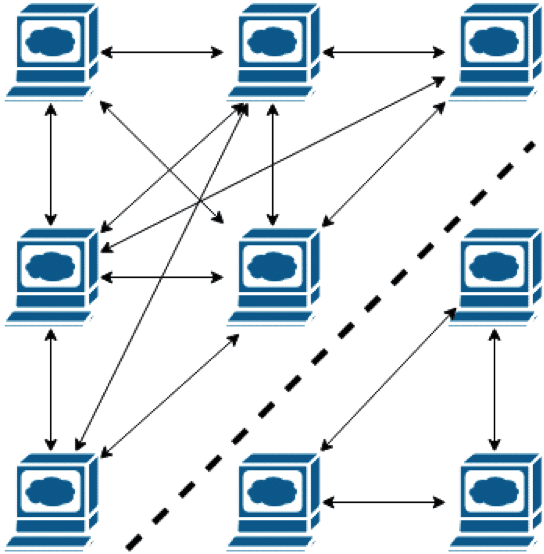
nodes lose connectivity to the rest of the cluster resulting in network partition
In the case of network partitioning, a distributed system can maintain only one of the two following characteristics: consistency or availability. A consistency can be maintained but at the expense of availability and vice versa. This trade-off is commonly known as the CAP theorem.
State consistency
When the state is shared between multiple nodes and each of them makes changes independently, the system’s global state is inconsistent until nodes exchange information about these changes. It can become a problem when a client requests a data from a node, which hasn’t received an update yet and gets outdated data and then tries to modify it. The system ends up in a situation when two nodes send conflicting change requests at the same time. There are several ways of how the system can handle it:
- one write-only node with multiple read-only replicas
- Action: cluster elects a write-only node that will be receiving change requests and serving as a source of truth to the other nodes
- Advantages:
- a cluster can select a new write node in case of failure
- high read scalability – new read-only nodes can be easily added to the cluster
- Downsides:
- a limited write scalability – system’s write performance is limited by a single node’s computing power
- write node becomes a single point of failure due to vulnerability to byzantine failures
- the system cannot receive change requests during a write node’s unavailability or election
- possible state inconsistency, when write node didn’t make it propagate all changes before failure and reboot, but a new write node has been elected (two write nodes at the same time)
- Applications:
- systems, where read requests highly outweigh write requests
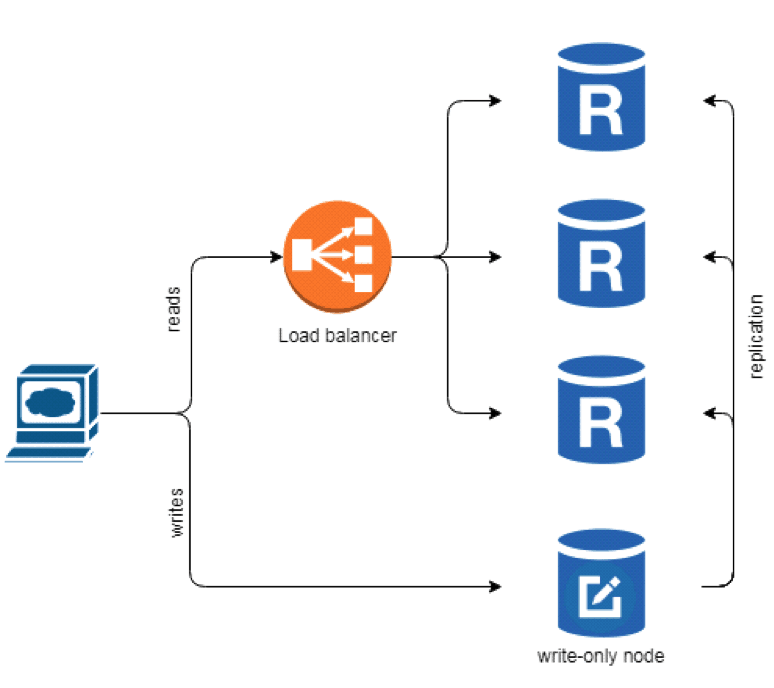
system architecture with read-only replicas
- locking
- Action: only a node, which holds a lock on an object is allowed to make changes
- Advantages:
- moderate scalability potential – lock acknowledgement process extends with each new node
- Downsides:
- vulnerability to byzantine behaviour in case one of the nodes goes rogue and bypasses locking protocol
- increased write latency due to the initial lock acknowledgement process
- performance decreases in case of frequent or simultaneous changes to the same objects
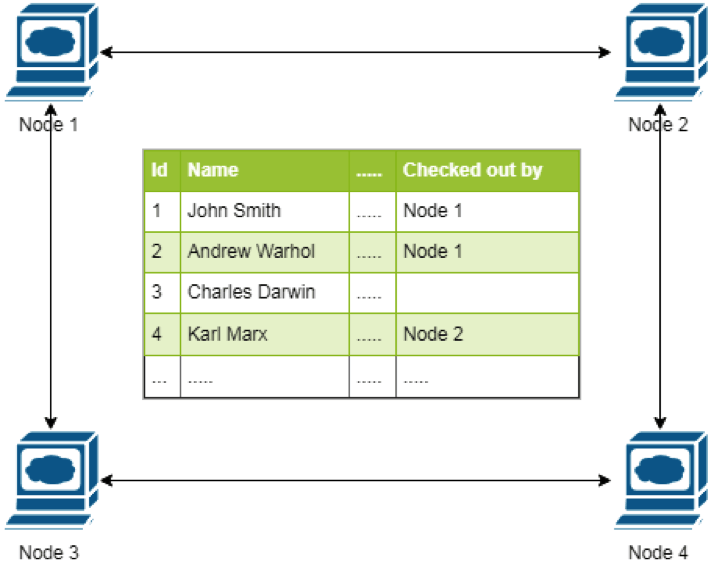
ledger with exclusive write locks
- sharding
- Action: the state is divided into disjoint sets and managed independently by different subclusters
- Advantages:
- high scalability potential, because all traffic is scattered across multiple nodes
- high reliability, because the failure of one set doesn’t influence others
- can be combined with the previous architectures
- Downsides:
- limited applications – it’s hard to find clear data boundaries
- each individual node is still susceptible to fail-stop behaviour
- Applications:
- microservices
- multitenant systems
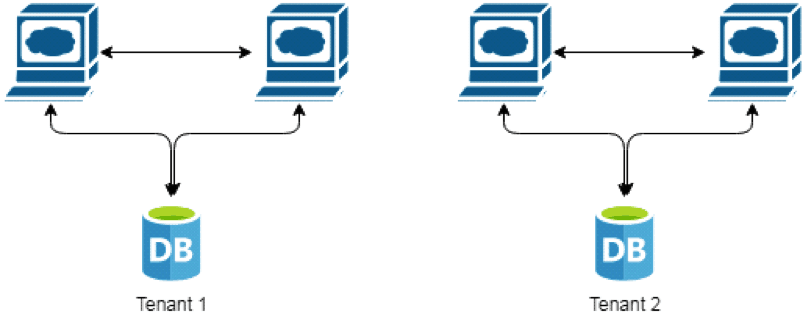
system with two disjoint datasets
- distributed voting
- Action: proposed change becomes persistent only if the vast majority of nodes accept it
- Advantages:
- resilient to byzantine failures, because cluster converges to an agreement even if the minority of nodes go rogue
- easy to implement
- mathematically proven to work
- average time required to achieve consensus can be calculated for known nodes
- Disadvantages:
- does not scale well because of the exponential growth of voting-related messages
- Applications:
- highly resilient systems with a small number of nodes
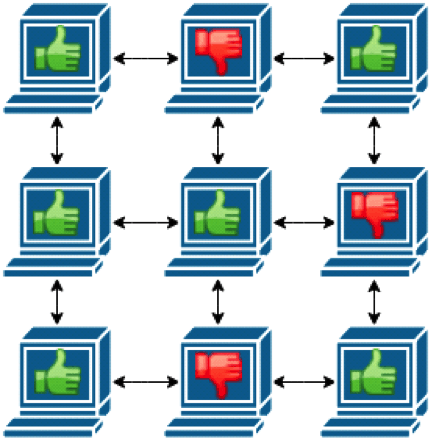
voting of nodes on system’s state
- proof of work
- Action: the first node which presents to a cluster a proof that it took an effort and did some moderately hard but feasible computation is granted the right to make a change
- Advantages:
- highly resilient to DoS attack, because messages with invalid or no proof of work are dropped by nodes
- moderate scalability, because cluster still has to converge into a consistent state and that takes time
- Disadvantages:
- slow, depending on computation difficulty to present a proof of work
- nodes with more computation power are more likely to present a proof of work first and decide upon the system’s state (security vulnerability)
- high electricity usage due to an increased amount of computation
- hashgraph
- Action: nodes exchange information about what each of them „thinks” happened in the system (events) and knowing what others know they can perform an internal virtual voting if asked about a state
- Advantages: resilient to byzantine failures because cluster converges to an agreement even when the state changes (events) being shared between nodes
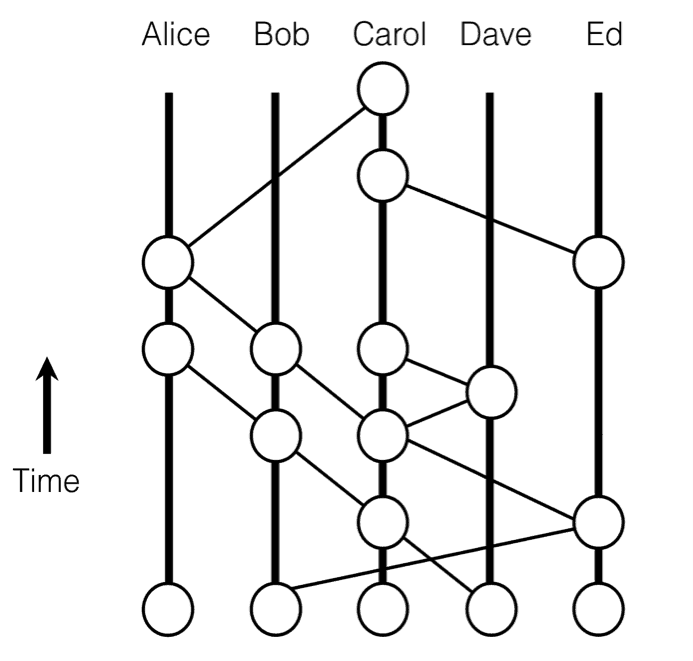
state changes (events) being shared between nodes
Summary
Each fault tolerance mechanism is advantageous over the other and costly to deploy.
Despite being helpful, the techniques presented above do not entirely solve the problem of how to design a fault-tolerant system. The probability of errors occurrence in the computer systems grows as they are applied to solve more complex problems. Fortunately, there are a lot of libraries and frameworks, which help to solve many popular problems like state consistency and replication in an out-of-the-box way. But they are just tools and if one wants them to work properly, they should be fully aware of their capabilities, as well as their drawbacks. It is very difficult to develop a flawless system and the absolute certainty of design correctness is rarely achieved. Nevertheless, some systems may be expected to provide reliability and availability and not to be stopped due to problems either in the hardware or the software. That’s why future development of mechanisms for fault tolerant systems will always be desired.